Content from Introducción a la Terminal
Last updated on 2023-04-24 | Edit this page
Estimated time: 5 minutes
Overview
Questions
- ¿Qué es una terminal y por qué utilizarla?
Objectives
- Explicar cómo se relaciona la terminal con el teclado, la pantalla, el sistema operativo y los programas de los usuarios.
- Explicar cuándo y por qué se deben utilizar interfaces de línea de comandos en lugar de interfaces gráficas.
Introducción
En su nivel más sencillo, las computadoras hacen cuatro cosas:
- ejecutar programas
- guardar datos
- comunicarse entre ellas
- interactuar con nosotros
Pueden hacer estas cosas de muchas maneras distintas, incluyendo conexiones directas entre cerebro-computadora o interfaces de voz. Aunque estas interfaces son cada vez más comunes, la mayoría de las interacciones aún se llevan a cabo a través de pantallas, ratones, pantallas táctiles y teclados. A pesar de que la mayoría de los sistemas operativos modernos se comunican con sus usuarios a través de ventanas, íconos y apuntadores, estas tecnologías no eran comunes sino hasta los años 80s. Las raíces de estas interfaces gráficas de usuario se remontan al trabajo de Doug Engelbart’s en los 60s, el cual podemos ver en lo que se ha denominado “La Madre de todos los Demos”.
Interfaz de Línea de Comandos
Remontándonos aún más allá, la única manera de interactuar con las computadoras tempranas era reorganizando sus cables. Después, entre los 50s y los 80s, la mayoría de la gente utilizaba impresoras de línea. Estos aparatos solo permitían generar entradas y salidas de letras, números y signos de puntuación que se encontraban en un teclado estándar, por lo que los lenguajes de programación y las interfaces con el software tuvieron que ser diseñados con esa limitante en mente.
A este tipo de interfaz se le denomina interfaz de línea de comandos (command-line interface, o CLI por sus siglas en inglés) para distinguirla de la interfaz gráfica de usuario (graphical user interface, o GUI) que es la que utilizan la mayoría de los usuarios actuales. El corazón del CLI es un ciclo conocido como read-evaluate-print loop, o REPL (ciclo lectura-ejecución-impresión): cuando el usuario teclea un comando y después presiona la tecla Enter, la computadora lo lee, ejecuta e imprime el resultado (también conocido como output). Después el usuario escribe otro comando y el ciclo continúa hasta que el usuario se desconecta del equipo.
La Terminal
Esta descripción hace pensar que el usuario envía comandos directamente a la computadora y que la computadora envía el resultado o salida directamente al usuario. De hecho, por lo general hay un programa intermediario conocido como terminal o línea de comandos. Lo que el usuario escribe se pasa a la terminal, la cual calcula qué comandos ejecutar y ordena al equipo su ejecución. (En inglés, a la terminal se le llama “shell”, que quiere decir concha, porque encierra al sistema operativo con el fin de ocultar algo de su complejidad y hacer más fácil la interacción con él.)
Una terminal es un programa como cualquier otro. Lo que la hace especial es que su trabajo es ejecutar otros programas, en lugar de realizar los cálculos en sí. La terminal más popular de Unix se llama Bash, que proviene de Bourne Again Shell (así llamada porque deriva de una versión previa escrita por Stephen Bourne). Bash es la terminal por defecto en la mayoría de las implementaciones modernas de Unix, y en la mayoría de los paquetes que proporcionan herramientas similares a las de Unix para Windows.
¿Por qué usarlo?
Utilizar bash o cualquier otra terminal a veces es mas cómodo para programar que utilizar un ratón. Los comandos son cortos (a menudo con sólo un par de caracteres de largo), sus nombres son frecuentemente crípticos, y su salida son líneas de texto en lugar de algo visual, como un gráfico. Por otra parte, con unas cuantas teclas la terminal nos permite combinar las herramientas existentes en potentes pipelines y manejar grandes volúmenes de datos automáticamente. Esta automatización no sólo nos hace más productivos, sino que también mejora la reproducibilidad de nuestros trabajo dado que permite repetir procesos de forma idéntica con unos simples comandos. Además, la línea de comandos es a menudo la forma más fácil de interactuar con máquinas remotas y superordenadores. La familiaridad con la terminal es casi esencial para utilizar una variedad de herramientas y recursos especializados, incluyendo sistemas de computación de alto rendimiento. A medida que los clusters y los sistemas de computación en la nube se vuelven más populares para el análisis de datos científicos, ser capaz de interactuar con ellos se convierte en una habilidad necesaria. Podemos aprovechar las habilidades que adquiriremos en línea de comandos para abordar una amplia gama de preguntas científicas y desafíos computacionales.
Pipeline de Nelle: Punto de partida
Nelle Nemo, una bióloga marina, acaba de regresar de un estudio de seis meses del Giro del Pacífico Norte, en donde ha estado muestreando la vida marina gelatinosa en la Gran Mancha de Basura del Pacífico. Tiene 1,520 muestras en total, ahora necesita:
- Procesar cada muestra en una máquina de ensayo para medir la abundancia relativa de 300 proteínas diferentes. La salida de la máquina para una sola muestra es un archivo con una línea para cada proteína, y un archivo con la secuencia de cada proteína.
- Calcular las estadísticas de cada una de las proteínas por separado
usando un programa que su supervisor escribió llamado
goostat. - Comparar las estadísticas de cada proteína con las estadísticas
correspondientes de las otras proteínas utilizando un programa que
escribió uno de los estudiantes de doctorado llamado
goodiff. - Resumir los resultados. A su supervisor le gustaría mucho que su análisis estuviera listo para fin de mes, para que su artículo pueda aparecer en un próximo número especial de Aquatic Goo Letters.
La máquina de ensayo tarda aproximadamente media hora en procesar cada muestra. La buena noticia es que sólo se necesitan dos minutos para configurar cada ensayo. Dado que su laboratorio tiene ocho máquinas de ensayo que puede utilizar en paralelo, este paso “sólo” durará unas dos semanas.
La mala noticia es que si quiere ejecutar goostat
ygoodiff a mano, Nelle tendrá que ingresar los nombres de
los archivos y hacer clic en “Aceptar” 46,370 veces (1520 carreras de
goostat, más 300 * 299/2 (la mitad de 300 veces 299)
ejecuciones degoodiff). Dado que cada ejecución toma 30
segundos, le llevará más de dos semanas (sin dormir ni comer). Nelle no
sólo no cumpliría su plazo de entrega de resultados, sino que las
posibilidades de que escriba todos los comandos correctamente son
prácticamente cero.
Las siguientes lecciones explorarán una mejor alternativa para que Nelle realice su análisis. Más específicamente, explicaremos cómo puede usar la línea de comandos para automatizar los pasos repetitivos en su pipeline. Así, su computadora podrá trabajar las 24 horas del día mientras ella escribe su artículo. Además, una vez que Nelle haya generado un pipeline podrá usarlo de nuevo cada vez que colecte nuevos datos.
Key Points
- Una terminal es un programa cuyo objetivo principal es leer comandos y ejecutar otros programas.
- Las principales ventajas de la terminal son su alta relación acción-tecla, su soporte para la automatización de tareas repetitivas, y que puede utilizarse para acceder a otras máquinas en una red.
- Las desventajas principales de la terminal son su naturaleza primordialmente textual y que sus comandos y operación pueden llegar a ser muy crípticos.
Content from Navegación de archivos y directorios
Last updated on 2023-04-24 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- ¿Cómo puedo moverme dentro de mi computadora?
- ¿Cómo puedo ver qué archivos y directorios tengo?
- ¿Cómo puedo especificar la ubicación de un archivo o directorio en mi computadora?
Objectives
- Explicar las similitudes y diferencias entre un archivo y un directorio.
- Convertir una ruta absoluta en una ruta relativa y viceversa.
- Construir rutas absolutas y relativas que identifican archivos y directorios específicos.
- Explicar los pasos del ciclo de lectura-ejecución-impresión de la terminal.
- Identificar el comando, opciones y nombres de archivo en una llamada de línea de comandos.
- Demostrar el uso del autocompletado con el tabulador y explicar sus ventajas.
La parte del sistema operativo responsable de administrar archivos y directorios se le denomina sistema de archivos (file system). Organiza nuestros datos en archivos que contienen información, y directorios (también llamados “carpetas”), que contienen archivos u otros directorios.
Varios comandos se utilizan con frecuencia para crear, inspeccionar, cambiar el nombre y eliminar archivos y directorios. Para comenzar a explorarlos, abramos una terminal:
La magia de preparación
Si escribes el comando: PS1='$ ' en tu terminal, seguido
de presionar la tecla ‘Enter’, tu ventana se verá como nuestro ejemplo
en esta lección. Esto no es necesario para continuar así que lo dejamos
a tu criterio.
El signo $ es un prompt, que nos
muestra que la terminal está esperando una entrada; tu terminal puede
usar un carácter diferente como prompt y puede agregar información antes
de él. Al teclear comandos, ya sea a partir de estas lecciones o de
otras fuentes, no escribas el prompt ($), sólo los comandos que
le siguen.
Escribe el comando whoami, luego presiona la tecla Enter
para enviar el comando a la terminal. La salida de este comando es el ID
del usuario actual, es decir, nos muestra como quién nos identifica la
terminal:
OUTPUT
nelleMás específicamente, cuando escribimos whoami la
terminal:
- encuentra un programa llamado
whoami, - ejecuta ese programa,
- muestra la salida de ese programa, luego
- muestra un nuevo prompt para decirnos que está listo para más comandos.
Variaciones en el username
En esta lección, hemos utilizado el nombre de usuario
nelle (asociado a nuestra científica hipotética Nelle) en
todos los ejemplos de entrada y salida. Sin embargo, cuando escribas los
comandos de esta lección en tu computadora, deberías ver y usar algo
diferente, específicamente, el username asociado con tu
cuenta de usuario en la computadora que estás utilizando. Este
username será la salida de whoami. En los
ejemplos siguientes, nelle siempre será reemplazado por ese
username.
Comandos desconocidos
Recuerda, la terminal es un programa que llama a otros programas en lugar de realizar los cálculos ella misma. Los comandos que escribes en la terminal deben ser los nombres de programas existentes. Si tecleas el nombre de un programa que no existe y oprimes Enter, verás un mensaje de error similar a este:
ERROR
-bash: mycommand: command not foundLa terminal te dice que no puede encontrar el programa
mycommand porque este programa no existe en tu computadora.
En este curso aprenderás varios comandos, pero existen muchos más de los
que mencionaremos.
Averiguemos dónde estamos, ejecutando el comando pwd
(que significa “imprime directorio de trabajo” - “print working
directory”). En cualquier momento, nuestro directorio
actual es nuestro directorio predeterminado, es decir, el
directorio que la computadora supone queremos ejecutar comandos a menos
que especifiquemos explícitamente otra cosa. En este caso la respuesta
de la computadora es /Users/nelle, el cual es el directorio
de inicio de Nelle, también conocido como su directorio
home:
OUTPUT
/Users/nelleVariaciones en el Directorio de Inicio
El directorio home puede lucir diferente en
distintos sistemas operativos. En Linux puede verse como
/home/nelle, en Windows puede ser similar a
C:\Documents and Settings\nelle o
C:\Users\nelle (pueden variar según la versión de Windows
que estés utilizando). En los ejemplos que siguen utilizaremos la salida
de Mac como estándar. Linux y Windows pueden variar ligeramente, pero
lucen similares en general.
Para entender lo que es un “directorio home” echemos un vistazo a cómo se organiza el sistema de archivos. Como ejemplo, discutiremos el sistema de archivos en la computadora de nuestra científica Nelle. Después de este ejemplo, aprenderás comandos para explorar tu propio sistema de archivos. Se parecerá a este, pero no será exactamente idéntico.
En la computadora de Nelle, el sistema de archivos se ve así:

En la parte superior está el directorio raíz o
root que contiene todo lo demás. Nos referimos a este
directorio usando un caracter de barra / por si solo; esta
es la barra al inicio de /Users/nelle.
Dentro de ese directorio hay otros directorios: bin (que
es donde se almacenan algunos programas preinstalados),
data (para archivos de datos diversos), Users
(donde se encuentran los directorios personales de los usuarios),
tmp (para archivos temporales que no necesitan ser
almacenados a largo plazo), etcétera.
Sabemos que nuestro directorio actual de trabajo
/Users/nelle se almacena dentro de/Users
porque /Users es la primera parte de su nombre. Igualmente,
sabemos que /Users se almacena dentro del directorio
raíz/ porque su nombre comienza con /.
Diagonales
Observa que hay dos significados para el carácter /.
Cuando aparezca antes del nombre de archivo o directorio, se refiere al
directorio root. Cuando aparezca dentro de un
nombre, es solo un separador.
Dentro de /Users, encontramos un directorio para cada
usuario con una cuenta en la máquina de Nelle, sus colegas Mummy y
Wolfman.

Los archivos de Mummy se almacenan en /Users/imhotep,
los de Wolfman están en /Users/larry, y los de Nelle en
/Users/nelle. Dado que Nelle es el usuario en nuestros
ejemplos, es por eso que recibimos /Users/nelle como
nuestro directorio personal. Normalmente, cada vez que abres una nueva
terminal te encontrarás en tu directorio home.
Ahora vamos a aprender el comando que nos permitirá ver el contenido
de nuestro sistema de archivos. Podemos ver lo que hay en nuestro
directorio personal ejecutando ls, que significa
“listar”:
OUTPUT
Applications Documents Library Music Public
Desktop Downloads Movies Pictures(Una vez más, tus resultados pueden ser ligeramente diferentes dependiendo de tu sistema operativo y cómo has personalizado tu sistema de archivos.)
ls imprime los nombres de los archivos y directorios en
el directorio actual en orden alfabético, dispuestos ordenadamente en
columnas. Podemos hacer su salida más comprensible usando la opción o
flag -F, que le indica a ls
que agregue un /a los nombres de los directorios:
OUTPUT
Applications/ Documents/ Library/ Music/ Public/
Desktop/ Downloads/ Movies/ Pictures/ls permite muchas otras flags. Para
averiguar cuales son, podemos escribir:
OUTPUT
Usage: ls [OPTION]... [FILE]...
List information about the FILEs (the current directory by default).
Sort entries alphabetically if none of -cftuvSUX nor --sort is specified.
Mandatory arguments to long options are mandatory for short options too.
-a, --all do not ignore entries starting with .
-A, --almost-all do not list implied . and ..
--author with -l, print the author of each file
-b, --escape print C-style escapes for nongraphic characters
--block-size=SIZE scale sizes by SIZE before printing them; e.g.,
'--block-size=M' prints sizes in units of
1,048,576 bytes; see SIZE format below
-B, --ignore-backups do not list implied entries ending with ~
-c with -lt: sort by, and show, ctime (time of last
modification of file status information);
with -l: show ctime and sort by name;
otherwise: sort by ctime, newest first
-C list entries by columns
--color[=WHEN] colorize the output; WHEN can be 'always' (default
if omitted), 'auto', or 'never'; more info below
-d, --directory list directories themselves, not their contents
-D, --dired generate output designed for Emacs' dired mode
-f do not sort, enable -aU, disable -ls --color
-F, --classify append indicator (one of */=>@|) to entries
--file-type likewise, except do not append '*'
--format=WORD across -x, commas -m, horizontal -x, long -l,
single-column -1, verbose -l, vertical -C
--full-time like -l --time-style=full-iso
-g like -l, but do not list owner
--group-directories-first
group directories before files;
can be augmented with a --sort option, but any
use of --sort=none (-U) disables grouping
-G, --no-group in a long listing, don't print group names
-h, --human-readable with -l and/or -s, print human readable sizes
(e.g., 1K 234M 2G)
--si likewise, but use powers of 1000 not 1024
-H, --dereference-command-line
follow symbolic links listed on the command line
--dereference-command-line-symlink-to-dir
follow each command line symbolic link
that points to a directory
--hide=PATTERN do not list implied entries matching shell PATTERN
(overridden by -a or -A)
--indicator-style=WORD append indicator with style WORD to entry names:
none (default), slash (-p),
file-type (--file-type), classify (-F)
-i, --inode print the index number of each file
-I, --ignore=PATTERN do not list implied entries matching shell PATTERN
-k, --kibibytes default to 1024-byte blocks for disk usage
-l use a long listing format
-L, --dereference when showing file information for a symbolic
link, show information for the file the link
references rather than for the link itself
-m fill width with a comma separated list of entries
-n, --numeric-uid-gid like -l, but list numeric user and group IDs
-N, --literal print raw entry names (don't treat e.g. control
characters specially)
-o like -l, but do not list group information
-p, --indicator-style=slash
append / indicator to directories
-q, --hide-control-chars print ? instead of nongraphic characters
--show-control-chars show nongraphic characters as-is (the default,
unless program is 'ls' and output is a terminal)
-Q, --quote-name enclose entry names in double quotes
--quoting-style=WORD use quoting style WORD for entry names:
literal, locale, shell, shell-always,
shell-escape, shell-escape-always, c, escape
-r, --reverse reverse order while sorting
-R, --recursive list subdirectories recursively
-s, --size print the allocated size of each file, in blocks
-S sort by file size, largest first
--sort=WORD sort by WORD instead of name: none (-U), size (-S),
time (-t), version (-v), extension (-X)
--time=WORD with -l, show time as WORD instead of default
modification time: atime or access or use (-u);
ctime or status (-c); also use specified time
as sort key if --sort=time (newest first)
--time-style=STYLE with -l, show times using style STYLE:
full-iso, long-iso, iso, locale, or +FORMAT;
FORMAT is interpreted like in 'date'; if FORMAT
is FORMAT1<newline>FORMAT2, then FORMAT1 applies
to non-recent files and FORMAT2 to recent files;
if STYLE is prefixed with 'posix-', STYLE
takes effect only outside the POSIX locale
-t sort by modification time, newest first
-T, --tabsize=COLS assume tab stops at each COLS instead of 8
-u with -lt: sort by, and show, access time;
with -l: show access time and sort by name;
otherwise: sort by access time, newest first
-U do not sort; list entries in directory order
-v natural sort of (version) numbers within text
-w, --width=COLS set output width to COLS. 0 means no limit
-x list entries by lines instead of by columns
-X sort alphabetically by entry extension
-Z, --context print any security context of each file
-1 list one file per line. Avoid '\n' with -q or -b
--help display this help and exit
--version output version information and exit
The SIZE argument is an integer and optional unit (example: 10K is 10*1024).
Units are K,M,G,T,P,E,Z,Y (powers of 1024) or KB,MB,... (powers of 1000).
Using color to distinguish file types is disabled both by default and
with --color=never. With --color=auto, ls emits color codes only when
standard output is connected to a terminal. The LS_COLORS environment
variable can change the settings. Use the dircolors command to set it.
Exit status:
0 if OK,
1 if minor problems (e.g., cannot access subdirectory),
2 if serious trouble (e.g., cannot access command-line argument).
GNU coreutils online help: <http://www.gnu.org/software/coreutils/>
Full documentation at: <http://www.gnu.org/software/coreutils/ls>
or available locally via: info '(coreutils) ls invocation'Muchos comandos bash y programas que la gente ha escrito que se
pueden ejecutar desde el bash, aceptan la opción --help
para mostrar más información sobre cómo usar los comandos o
programas.
Para más información sobre cómo usar ls podemos escribir
man ls. man es el comando “manual” de Unix:
imprime la descripción de un comando y sus opciones, y (si tienes
suerte) proporciona algunos ejemplos de cómo usarlo.
man y Git para Windows
La terminal proporcionada por Git para Windows no incluye soporte
para el comando man. Una búsqueda en la web de
unix man page COMMAND (por ejemplo,
unix man page grep) proporciona enlaces a numerosas copias
en línea del manual de Unix. Por ejemplo, GNU proporciona enlaces a sus
Manuales, que
incluyen grep, y
utilidades
básicas de GNU, que cubre muchos comandos incluidos en esta
lección.
Para navegar por las páginas de man, las teclas de
flecha arriba y abajo te permiten moverte línea por línea, las teclas
“b” y la barra espaciadora permiten saltar hacia arriba y hacia abajo
una página a la vez. Puedes salir de las páginas man
escribiendo “q”.
Aquí podemos ver que nuestro directorio home
contiene principalmente subdirectorios. Cualquier
nombre en la salida que no tenga barras se refiere a
archivos comunes y corrientes. Observa que hay un
espacio entre ls y -F: sin él, la terminal
cree que estamos tratando de ejecutar un comando llamado
ls-F, el cual no existe.
Parámetros vs. Argumentos
De acuerdo con Wikipedia, los términos argumento y parámetro significan cosas ligeramente diferentes. En la práctica, sin embargo, la mayoría de la gente los usa indistintamente para referirse a los términos que acompañan a un comando. Considera el siguiente ejemplo:
ls es el comando, -lh son
flags (u opciones), y Documents es el
argumento.
También podemos usar ls para ver el contenido de un
directorio diferente. Veamos nuestro directorio Desktop
ejecutandols -F Desktop, es decir, el comando
ls con flag -F y el
argumento Desktop. El argumento
Desktop le dice a ls que queremos una lista de
algo distinto a nuestro directorio actual.
OUTPUT
data-shell/La salida debe ser una lista de todos los archivos y subdirectorios
en tu Desktop, incluido el directorio
data-shell que descargaste al comienzo de la lección. Echa
un vistazo a tu escritorio para confirmar que la salida es correcta.
Como puedes ver ahora, el uso de una terminal está basado de la idea de que tus archivos se organizan en un sistema de archivos jerárquico. Organizar las cosas jerárquicamente nos ayuda a realizar un seguimiento de nuestro trabajo: es posible poner centenares de archivos en nuestro directorio home, así como es posible acumular cientos de papeles impresos en nuestro escritorio, pero es una estrategia muy poco eficiente.
Ahora que sabemos que el directorio data-shell se
encuentra en Desktop, podemos hacer dos cosas.
Primero, podemos ver su contenido, usando la misma estrategia que
antes, pasando un nombre de directorio a ls:
OUTPUT
creatures/ molecules/ notes.txt solar.pdf
data/ north-pacific-gyre/ pizza.cfg writing/En segundo lugar, podemos cambiar nuestra ubicación a un directorio diferente, por lo que ya no estaremos ubicados en nuestro directorio home.
El comando para cambiar de ubicación es cd, seguido del
nombre de un directorio para cambiar nuestro directorio de trabajo.
cd significa “cambio de directorio” (change directory), lo
cual es un poco engañoso: el comando no cambia el directorio, cambia la
idea de la terminal de en qué directorio estamos.
Digamos que queremos pasar al directorio data que vimos
anteriormente. Podemos utilizar la siguiente serie de comandos para
llegar allí:
Estos comandos nos moverán del directorio home al
directorio Desktop, luego al directorio data-shell, y
finalmente al directorio data. cd no imprime
nada, pero si ejecutamos pwd después de esto, podemos ver
que ahora estamos en /Users/nelle/Desktop/data-shell/data.
Si ejecutamos ls ahora sin argumentos, se listan los
contenidos de /Users/nelle/Desktop/data-shell/data, porque
ahí es donde estamos ahora:
OUTPUT
/Users/nelle/Desktop/data-shell/dataOUTPUT
amino-acids.txt elements/ pdb/ salmon.txt
animals.txt morse.txt planets.txt sunspot.txtAhora sabemos cómo bajar por el árbol de directorios, pero ¿cómo subimos (regresamos)? Podemos probar lo siguiente:
ERROR
-bash: cd: data-shell: No such file or directory¡Pero tenemos un error! ¿Por qué pasa esto?
Con los métodos aprendidos hasta ahora, cd sólo puede
ver subdirectorios dentro del directorio actual. Existen distintas
maneras de ver los directorios que se encuentran encima de tu ubicación
actual; empezaremos con el más simple.
Existe un acceso directo en la terminal para subir un nivel de directorio que se ve así:
.. es un nombre de directorio especial que significa “el
directorio que contiene a este”, o más brevemente, el
padre del directorio actual. Por supuesto, si
ejecutamos pwd después de ejecutarcd ..,
volvemos a /Users/nelle/Desktop/data-shell:
OUTPUT
/Users/nelle/Desktop/data-shellNormalmente no aparece el directorio especial .. cuando
ejecutamosls. Si queremos mostrarlo, podemos dar a
ls la opción -a:
OUTPUT
./ creatures/ notes.txt
../ data/ pizza.cfg
.bash_profile molecules/ solar.pdf
Desktop/ north-pacific-gyre/ writing/-a significa “mostrar todo”; obliga a ls a
mostrarnos nombres de archivos y directorios que comienzan con
., como .. (que, si estamos
en/Users/nelle, hace referencia al directorio
/Users) Como puedes ver, también muestra otro directorio
especial que se llama simplemente ., que significa “el
directorio de trabajo actual”. Puede parecer redundante tener un nombre
para él, pero veremos algunos usos para ello en el transcurso de este
curso.
Nota que varias flags del mismo comando pueden
combinarse en el mismo -, sin espacios entre los
argumentos: ls -F -a es equivalente a
ls -Fa.
Otros archivos ocultos
Además de los directorios ocultos .. y .,
también puedes ver un archivo llamado .bash_profile. Este
archivo normalmente contiene configuraciones de ajuste de la terminal.
También puedes ver otros archivos y directorios que comienzan con
.. Estos son generalmente archivos y directorios que se
utilizan para configurar diferentes programas en tu computadora. El
prefijo . se utiliza para evitar que archivos de
configuración llenen la terminal cuando un comando ls
estándar se utiliza.
Ortogonalidad
Los nombres especiales . y .. no son
exclusivos de cd; son interpretados de la misma manera por
todos los programas. Por ejemplo, si estamos en
/Users/nelle/data, el comando ls .. nos dará
una lista de/Users/nelle. Cuando los significados de las
partes son los mismos, no importa cómo se combinan, los programadores
dicen que son ortogonales: los sistemas ortogonales
tienden a ser más fáciles de aprender porque hay menos casos especiales
y excepciones que recordar.
Estos son entonces los comandos básicos para navegar por el sistema
de archivos de tu computadora: pwd,ls y
cd. Exploremos algunas variaciones de estos comandos. ¿Qué
pasa si escribes cd por sí solo, sin dar un directorio?
¿Cómo puedes comprobar lo que sucedió? ¡pwd nos da la
respuesta!
OUTPUT
/Users/nelleResulta que cd sin un argumento te devolverá a tu
directorio home, lo cual es genial si te has perdido en
tu propio sistema de archivos.
Vamos a intentar volver al directorio data que
utilizamos antes. La última vez, usamos tres comandos, pero en realidad
podemos enlazar la lista de directorios para llegar a data
en un solo paso:
Comprueba que nos hemos movido al lugar correcto ejecutando
pwd y ls -F.
Si queremos subir un nivel desde el directorio de datos, podríamos
usar cd ... Pero hay otra manera de moverse a cualquier
directorio, independientemente de tu ubicación actual.
Hasta ahora, al especificar nombres de directorio, o incluso una ruta
de directorio (como anteriormente), hemos estado usando caminos
relativos. Cuando utilizas una ruta relativa con un comando
como ls ocd, la terminal intenta encontrar esa
ubicación desde donde estamos, en lugar de la raíz del sistema de
archivos.
Sin embargo, es posible especificar la ruta absoluta
a un directorio incluyendo su ruta completa desde el directorio raíz,
que está indicado por una diagonal principal. Esta /
principal le dice a la computadora que siga el camino desde la raíz del
sistema de archivos, por lo que siempre se refiere a un sólo directorio,
sin importar donde estemos cuando ejecutamos el comando.
Esto nos permite pasar a nuestro directorio data-shell
desde cualquier lugar del sistema de directorios (incluyendo desde
data). Para encontrar el camino absoluto que estamos
buscando, podemos usar pwd y luego extraer la pieza que
necesitamos para movernos a data-shell.
OUTPUT
/Users/nelle/Desktop/data-shell/dataEjecuta pwd y ls -F para asegurarte de que
estás en el directorio que esperas.
Dos atajos más
La terminal interpreta el carácter ~ (tilde) al inicio
de una ruta como “el directorio inicial del usuario actual”. Por
ejemplo, si el home de Nelle es
/Users/nelle, entonces~/data es equivalente a
/Users/nelle/data. Esto sólo funciona si es el primer
carácter en la ruta: aqui/alla/~/otrolado no es
aquí/alla/Users/nelle/otrolado.
Otro atajo es el carácter - (guión). cd lo
interpreta como el directorio anterior en el que estaba, lo
cual es más rápido que tener que recordar, y luego escribir, la ruta
completa. Esta es una manera muy eficiente de ir y venir entre
directorios. La diferencia entre cd .. y cd -
es que el primero te mueva hacia adelante, mientras que el
último te regresa. Puedes pensar en ello como el botón
último canal en el control remoto de tu televisión.
Pipeline de Nelle: Organizando archivos
Sabiendo todo esto de archivos y directorios, Nelle está lista para
organizar los archivos que creará la máquina de análisis de proteínas.
Primero, Nelle crea un directorio llamado
north-pacific-gyre (para recordar de dónde provienen los
datos). Dentro de éste, crea un directorio llamado
2012-07-03, que es la fecha en que comenzó a procesar las
muestras. Solía utilizar nombres como conference-paper y
revised-results, pero se tornaban difíciles de entender
después de un par de años. (La gota que derramo el vaso fue cuando se
encontró creando un directorio denominado
revised-revised-results-3.)
Ordenando la salida
Nelle nombra sus directorios “año-mes-día”, con ceros a la cabeza para meses y días, porque la terminal muestra los nombres de archivos y directorios en orden alfabético. Si usara nombres de mes, diciembre vendría antes de julio; si no utiliza ceros a la izquierda, Noviembre (‘11’) vendría antes de julio (‘7’). Del mismo modo, poner el año primero significa que junio de 2012 aparecerá antes de junio de 2013.
Cada una de sus muestras físicas está etiquetada según la convención
de su laboratorio con un identificador único de diez caracteres, tal
como “NENE01729A”. Esto es lo que utilizó en su registro de la colección
para registrar la ubicación, el tiempo, la profundidad y otras
características de la muestra, por lo que decidió utilizarlo como parte
del nombre de cada archivo de datos. Dado que la salida de la máquina de
ensayo es texto sin formato, ella llamará a sus archivos
NENE01729A.txt, NENE01812A.txt, y así
sucesivamente. Todos los 1,520 archivos estarán en el mismo
directorio.
Ahora en su directorio actual data-shell, Nelle puede
ver qué archivos tiene usando el comando:
Esto es mucho que teclear, pero puede permitir que la terminal haga la mayor parte del trabajo a través de lo que se llama autocompletado con el tabulador. Si escribe:
y después presiona el tabulador (la tecla de tabulador en su teclado), la terminal completa automáticamente el nombre del directorio por ella:
Si presiona el tabulador otra vez, Bash añadirá
2012-07-03/ al comando, ya que es el único
autocompletamiento posible. Presionar el tabulador de nuevo no hace
nada, ya que hay 19 posibilidades; presionar el tabulador dos veces
muestra una lista de todos los archivos, y así sucesivamente. Esto se
denomina autocompletado con el tabulador, y lo veremos
en muchas otras herramientas a medida que avancemos.
Rutas Absolutas vs Relativas
A partir de /Users/amanda/data/, ¿Cuál de los siguientes
comandos podría Amanda usar para navegar a su directorio de inicio, que
es /Users/amanda?
cd .cd /cd /home/amandacd ../..cd ~cd homecd ~/data/..cdcd ..
- No:
.significa el directorio actual. - No:
/significa el directorio raíz. - No: El directorio home de Amanda es
/Users/amanda. - No: sube dos niveles, es decir termina en
/Users. - Sí:
~significa el directorio home del usuario, en este caso/Users/amanda. - No: esto navegaría a un directorio
homeen el directorio actual, si existe. - Sí: innecesariamente complicado, pero correcto.
- Sí: un atajo para volver al directorio home del usuario.
- Sí: sube un nivel.
Resolución de ruta relativa
Si se utiliza el diagrama de sistema de directorios de abajo, si
pwd muestra /Users/thing, ¿Qué mostrará
ls -F ../backup?
../backup: No such file or directory2012-12-01 2013-01-08 2013-01-272012-12-01/ 2013-01-08/ 2013-01-27/original/ pnas_final/ pnas_sub/

- No: sí existe un directorio
backupen/Users. - No: este es el contenido de
Users/thing/backup, pero con..pedimos un nivel más arriba. - No: lee la explicación anterior.
- Sí:
../backupse refiere a/Users/backup.
ls comprensión de lectura
Suponiendo una estructura de directorio como en la figura anterior,
si pwd muestra /Users/backup, y
-r le dice a ls que muestre el resultado en
orden inverso, ¿qué comando mostrará:
OUTPUT
pnas_sub/ pnas_final/ original/ls pwdls -r -Fls -r -F /Users/backup- #2 y #3, pero no #1.
- No:
pwdno es el nombre de un directorio. - Sí:
lssin argumento de directorio lista archivos y directorios en el directorio actual. - Sí: utiliza explícitamente el camino absoluto.
- Correcto: vea las explicaciones arriba.
Explorando más argumentos de
ls
¿Qué hace el comando ls cuando se utiliza con los
argumentos-l y -h?
Algunos de sus resultados son sobre propiedades que no cubrimos en esta lección (tales como permisos de archivo y propiedad), sin embargo, el resto debe ser útil.
El argumento -l hace que ls utilice un
formato de lista largo, mostrando no sólo los nombres
de archivo/directorio, sino también información adicional como el tamaño
del archivo y la hora de su última modificación. El argumento
-h hace que el tamaño del archivo sea
“human readable” (legible por humanos), es decir,
muestra algo como 5.3K en lugar de5369.
Listando recursivamente y por tiempo
El comando ls -R enumera el contenido de los directorios
recursivamente, es decir, lista sus subdirectorios, subsubdirectorios,
etc. en orden alfabético en cada nivel. El comando ls -t
ordena el resultado según la fecha del último cambio, los archivos o
directorios más recientemente modificados aparecen primero. ¿En qué
orden muestra los resultados el usar ls -R -t? Pista:
ls -l usa un formato de lista larga para ver los
timestamps.
Los directorios se enlistan alfabéticamente en cada nivel, los archivos/directorios en cada directorio se ordenan por la hora del último cambio.
Key Points
- El sistema de archivos es responsable de administrar la información en el disco.
- La información se almacena en archivos, que a su vez se almacenan en directorios (carpetas).
- Los directorios también pueden almacenar otros directorios, formando un árbol de directorios.
-
cd pathcambia el directorio de trabajo actual. -
ls pathimprime un listado de un archivo o directorio específico;lspor si solo lista el contenido del directorio de trabajo actual. -
pwdimprime el directorio de trabajo actual del usuario. -
whoamimuestra la identidad actual del usuario. -
/es el directorio raíz de todo el sistema de archivos. - Una ruta relativa especifica una ubicación desde la ubicación actual.
- Una ruta absoluta especifica una ubicación desde la raíz del sistema de archivos.
- Los nombres de directorio en una ruta están separados por ‘/’ en Unix, pero por \ en Windows.
- ‘..’ significa ‘el directorio por encima del actual’; ‘.’ significa ‘el directorio actual’.
- La mayoría de los nombres de los archivos son
algo.extension. La extensión no es necesaria y no garantiza nada, pero normalmente se utiliza para indicar el tipo de datos en el archivo. - La mayoría de los comandos toman opciones (flags) que comienzan con un ‘-’.
Content from Trabajando con archivos y directorios
Last updated on 2023-04-24 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- ¿Cómo puedo crear, copiar y eliminar archivos y directorios?
- ¿Cómo puedo editar archivos?
Objectives
- Crear una jerarquía de directorios que coincida con un diagrama dado.
- Crear archivos en esa jerarquía usando un editor o copiando y renombrando archivos existentes.
- Mostrar el contenido de un directorio utilizando la línea de comandos.
- Eliminar archivos y/o directorios específicos.
Ahora sabemos cómo explorar archivos y directorios, pero ¿cómo los
creamos en primer lugar? Volvamos a nuestro directorio
data-shell en Desktop y utilicemos el comando
ls -F para ver lo que contiene:
OUTPUT
/Users/nelle/Desktop/data-shellOUTPUT
creatures/ molecules/ pizza.cfg
data/ north-pacific-gyre/ solar.pdf
Desktop/ notes.txt writing/Creemos un nuevo directorio llamado thesis usando el
comandomkdir thesis (que no genera una salida):
Como su nombre sugiere, mkdir significa “make
directory”, que significa “crear directorio” en inglés. Dado que
thesis es una ruta relativa (es decir, no inicia con una
barra oblicua /), el nuevo directorio se crea en la carpeta
de trabajo actual:
OUTPUT
creatures/ north-pacific-gyre/ thesis/
data/ notes.txt writing/
Desktop/ pizza.cfg
molecules/ solar.pdfDos maneras de hacer lo mismo
Usar la terminal para crear un directorio no es diferente de usar un
navegador de archivos gráfico. Si abres el directorio actual utilizando
el explorador de archivos gráfico de tu sistema operativo, el directorio
thesis aparecerá allí también. Si bien son dos formas
diferentes de interactuar con los archivos, los archivos y los
directorios con los que trabajamos son los mismos.
Buena nomenclatura para archivos y directorios
Usar nombres complicados para archivos y directorios pueden hacer tu vida muy complicada cuando se trabaja en la línea de comandos. Te ofrecemos algunos consejos útiles para nombrar tus archivos de ahora en adelante.
- No uses espacios en blanco.
Los espacios en blanco pueden hacer un nombre más significativo,
pero, dado que se utilizan para separar argumentos en la línea de
comandos, es mejor evitarlos en nombres de archivos y directorios.
Puedes utilizar - o_ en lugar de espacios en
blanco.
- No comiences el nombre con un
-(guión).
Los comandos tratan a los nombres que comienzan con -
como opciones.
- Utiliza únicamente letras, números,
.(punto),-(guión) y_(guión bajo).
Muchos otros caracteres tienen un significado especial en la línea de comandos y los aprenderemos durante esta lección. Algunos sólo harán que tu comando no funcione, otros pueden incluso hacer que pierdas datos.
Si necesitas referirte a nombres de archivos o directorios que tengan
espacios en blanco u otro carácter no alfanumérico, se debe poner el
nombre entre comillas dobles ("").
Dado que acabamos de crear el directorio thesis, aún se
encuentra vacío:
Cambiemos nuestro directorio de trabajo a thesis
usandocd, y a continuación, ejecutemos un editor de texto
llamado Nano para crear un archivo denominado
draft.txt:
¿Qué editor usar?
Cuando decimos, “nano es un editor de texto”, realmente
queremos decir “texto”: sólo funciona con datos de caracteres simples,
no con tablas, imágenes o cualquier otro formato amigable con el
usuario. Lo utilizamos en ejemplos porque es un editor muy sencillo que
permite funciones muy básicas. Sin embargo, por estas mismas cualidades,
podría ser insuficiente para necesidades de la vida real. En los
sistemas Unix (como Linux y Mac OS X) muchos programadores utilizan Emacs o Vim (ambos requieren más tiempo para
familiarizarse con ellos), o un editor gráfico como Gedit. En Windows puedes
utilizar Notepad ++.
Windows también tiene un editor interno llamado notepad que
se puede ejecutar desde la línea de comandos de la misma manera que
nano para los propósitos de esta lección.
Sea cual sea el editor que uses, necesitarás saber dónde busca y guarda archivos. Si lo inicias desde la terminal, usará (probablemente) el directorio de trabajo actual como ubicación predeterminada. Si utilizas el menú de inicio de tu computadora puede ser que los archivos se guarden en tu Desktop o el directorio de Documentos. Puedes cambiar de directorio destino navegando a otro directorio la primera vez guardes el archivo usando “Guardar como …”.
Escribamos algunas líneas de texto. Una vez que estemos contentos con
nuestro texto, podemos presionar Ctrl-O (presiona la tecla
Ctrl o Control y, mientras la mantienes presionada, oprime la tecla O)
para escribir nuestros datos en el disco (se nos preguntará en qué
archivo queremos guardar esto: presiona Enter para aceptar
el valor predeterminado sugerido draft.txt).
Una vez que nuestro archivo está guardado, podemos usar
Ctrl-X para salir del editor y volver a la terminal.
Tecla Control, Ctrl o ^
La tecla Control también se denomina tecla “Ctrl”. Hay varias maneras de indicar el uso de la tecla Control. Por ejemplo, una instrucción para presionar la tecla Control y, mientras la mantienes pulsada, presionar la tecla X, puede ser descrita de cualquiera de las siguientes maneras:
Control-XControl+XCtrl-XCtrl+X^XC-x
En nano, a lo largo de la parte inferior de la pantalla se lee
^G Get Help ^O WriteOut. Esto significa que puedes usar
Control-G para obtener ayuda yControl-O para
guardar tu archivo.
nano no deja ninguna salida en la pantalla después de
que salir del programa, pero ls ahora muestra que hemos
creado un archivo llamadodraft.txt:
OUTPUT
draft.txtLimpiemos un poco ejecutando rm draft.txt:
Este comando elimina archivos (rm es la abreviatura de
“remove”, “remover” en inglés). Si ejecutamos ls de nuevo,
la salida estará vacía una vez más, indicándonos que nuestro archivo ha
desaparecido:
Eliminar es para siempre
La terminal de Unix no tiene una papelera de reciclaje desde donde podamos restaurar archivos eliminados (aunque la mayoría de las interfaces gráficas de Unix sí lo tienen). En su lugar, cuando eliminamos archivos, los mismos se desvinculan del sistema de archivos para que su espacio de almacenamiento en disco pueda ser reciclado. Existen herramientas para encontrar y recuperar archivos eliminados, pero no hay garantía de que funcionen en todas las situaciones, ya que la computadora puede reciclar el espacio en disco del archivo en cuestión inmediatamente, perdiéndose de manera permanente.
Creemos de nuevo el archivo y después subamos un directorio a
/Users/nelle/Desktop/data-shell usando
cd ..:
OUTPUT
/Users/nelle/Desktop/data-shell/thesisOUTPUT
draft.txtSi tratamos de eliminar todo el directorio thesis usando
rm thesis, obtenemos un mensaje de error:
ERROR
rm: cannot remove `thesis': Is a directoryEsto ocurre porque rm normalmente trabaja sólo con
archivos, no con directorios.
Para realmente deshacernos de thesis también debemos
eliminar el archivo draft.txt. Podemos hacer esto con la
opción recursiva
para rm:
Un gran poder conlleva una gran responsabilidad
Eliminar los archivos en un directorio recursivamente puede ser una
operación muy peligrosa. Si nos preocupa lo que podríamos eliminar,
podemos añadir la opción “interactiva” -i a
rm, que nos pedirá confirmar cada paso.
BASH
$ rm -r -i thesis
rm: descend into directory ‘thesis'? y
rm: remove regular file ‘thesis/draft.txt'? y
rm: remove directory ‘thesis'? yEsto elimina todo el contenido en el directorio y después el directorio mismo, preguntando en cada paso para que se confirme la eliminación.
Vamos a crear el directorio y el archivo una vez más. (Ten en cuenta
que esta vez estamos ejecutando nano con la ruta de acceso
thesis/draft.txt, en lugar de ir al directorio
thesis y ejecutar nano en
draft.txt.)
OUTPUT
/Users/nelle/Desktop/data-shellOUTPUT
draft.txtdraft.txt no es un nombre particularmente informativo,
así que cambiemos el nombre del archivo usando el comando
mv, que es la abreviatura de “move” (mover):
El primer parámetro dice a mv lo que estamos
“moviendo”“, mientras que el segundo indica a dónde hay que moverlo. En
este caso estamos moviendo thesis/draft.txt a
thesis/quotes.txt, que tiene el mismo efecto que cambiar el
nombre del archivo. Como esperamos, ls nos muestra que
thesis ahora contiene un archivo llamado
quotes.txt:
OUTPUT
quotes.txtHay que tener cuidado al especificar el nombre del archivo destino,
ya que mv remplaza silenciosamente cualquier archivo
existente con el mismo nombre, provocando pérdida de datos. Un indicador
adicional, mv -i (o mv --interactive), se
puede utilizar para hacer que mv te pida confirmación antes
de sobrescribir.
Sólo por el gusto de la consistencia, mv también
funciona en directorios, es decir, no existe un comando separado
mvdir. Vamos a mover quotes.txt al directorio
de trabajo actual. Utilizamos mv una vez más, pero esta vez
sólo usaremos el nombre de un directorio como el segundo parámetro para
indicar a mv que queremos mantener el nombre de archivo,
pero poner el archivo en algún lugar nuevo. (es por eso que el comando
se llama “mover”.) En este caso, el nombre de directorio que usamos es
el nombre de directorio especial . que mencionamos
anteriormente.
El resultado es mover el archivo desde el directorio en el que estaba
en el directorio de trabajo actual. ls ahora nos muestra
que thesis está vacío:
Además, ls con un nombre de archivo o un nombre de
directorio como parámetro sólo lista ese archivo o directorio. Podemos
usar esto para ver que quotes.txt todavía está en nuestro
directorio actual:
OUTPUT
quotes.txtEl comando cp funciona muy bien comomv,
excepto que copia un archivo en lugar de moverlo. Podemos comprobar que
hizo lo correcto usando ls con dos rutas como parámetros —
como la mayoría de los comandos Unix, ls puede recibir
múltiples rutas a la vez:
OUTPUT
quotes.txt thesis/quotations.txtPara probar que hicimos una copia, eliminemos el archivo
quotes.txt del directorio actual y después ejecutemos el
mismo ls de nuevo.
ERROR
ls: cannot access quotes.txt: No such file or directory
thesis/quotations.txtEsta vez el error nos dice que no se puede encontrar
quotes.txt en el directorio actual, pero encuentra la copia
en thesis que no hemos borrado.
¿Qué hay en un nombre?
Tal vez notaste que todos los nombres de los archivos de Nelle son
“algo punto algo”, y en esta parte de la lección, usamos siempre la
extensión .txt. Esto es sólo una convención: podemos llamar
a un archivo mythesis o casi cualquier cosa que queramos.
Sin embargo, la mayoría de la gente usa nombres de dos partes para que
sea más fácil (para ellos y sus programas) diferenciar entre tipos de
archivos. La segunda parte de este nombre se llama la extensión
de nombre de archivo e indica qué tipo de datos contiene el
archivo: .txt señala un archivo de texto sin formato,
.pdf indica un documento PDF, .cfg es un
archivo de configuración lleno de parámetros para algún programa,
.png es una imagen PNG, y así sucesivamente.
Esto es sólo una convención, aunque una importante. Los archivos contienen solo bytes: depende de nosotros y de nuestros programas interpretar esos bytes de acuerdo a las reglas para archivos de texto, documentos PDF, archivos de configuración, imágenes, etc.
Nombrar una imagen PNG de una ballena como whale.mp3 no
lo convierte mágicamente en una grabación del canto de las ballenas,
aunque podría hacer que el sistema operativo intente abrirlo
con un reproductor de música cuando alguien hace doble clic en él.
Cambiando el nombre de archivos
Supón que has creado un archivo .txt en tu directorio
actual para incluír una lista de las pruebas estadísticas que necesitas
hacer para analizar tus datos, y lo llamarás:
statstics.txt
Después de crear y guardar este archivo, te das cuenta de que has escrito mal el nombre del archivo. Si deseas corregir el error, ¿cuál de los siguientes comandos podrías utilizar para hacerlo?
cp statstics.txt statistics.txtmv statstics.txt statistics.txtmv statstics.txt .cp statstics.txt .
- No. Mientras esto crearía un archivo con el nombre correcto, el archivo con nombre incorrecto todavía existiría en el directorio y necesitaría ser borrado.
- Sí, esto funcionaría para renombrar el archivo.
- No, el punto (.) indica dónde mover el archivo, pero no proporciona un nuevo nombre de archivo; no pueden crearse nombres de archivo idénticos.
- No, el punto (.) indica dónde copiar el archivo, pero no proporciona un nuevo nombre de archivo; no pueden crearse nombres de archivo idénticos.
Moviendo y copiando
¿Cuál es la salida del último comando ls en la secuencia
que se muestra a continuación?
OUTPUT
/Users/jamie/dataOUTPUT
proteins.datBASH
$ mkdir recombine
$ mv proteins.dat recombine
$ cp recombine/proteins.dat ../proteins-saved.dat
$ lsproteins-saved.dat recombinerecombineproteins.dat recombineproteins-saved.dat
Comenzamos en el directorio /Users/jamie/data y creamos
una nueva carpeta llamada recombine. La segunda línea mueve
(mv) el archivo proteins.dat a la nueva
carpeta (recombine). La tercera línea hace una copia del
archivo que acabamos de mover. La parte difícil aquí es en dónde se
copió el archivo. Recuerda que .. significa “subir un
nivel”, por lo que el archivo copiado ahora está en
/Users/jamie. Observa que .. se interpreta con
respecto al directorio actual de trabajo, no con
respecto a la ubicación del archivo que se está copiando. Por lo tanto,
lo único que se mostrará usando ls (en /Users/jamie/data)
es la carpeta recombine.
- No, consulta la explicación anterior.
proteins-saved.datse encuentra en/Users/jamie - Sí
- No, consulta la explicación anterior.
proteins.datse encuentra en/Users/jamie/data/recombine - No, consulta la explicación anterior.
Proteins-saved.datse encuentra en/Users/jamie
Organización de directorios y archivos
Jamie está trabajando en un proyecto y nota que sus archivos no están muy bien organizados:
OUTPUT
analyzed/ fructose.dat raw/ sucrose.datLos archivos fructose.dat ysucrose.dat
contienen la salida de sus análisis. ¿Qué comando(s) cubierto(s) en esta
lección necesita ejecutar para que los comandos a continuación produzcan
la salida mostrada?
OUTPUT
analyzed/ raw/OUTPUT
fructose.dat sucrose.datCopiar con varios archivos
Para este ejercicio puedes probar los comandos del directorio
data-shell/data En el ejemplo que sigue, ¿qué hace
cp cuando se le dan varios nombres de archivo y un nombre
de directorio?:
En el siguiente ejemplo, ¿qué hace cp cuando se le dan
tres o más nombres de archivo?
OUTPUT
amino-acids.txt animals.txt backup/ elements/ morse.txt pdb/ planets.txt salmon.txt sunspot.txtSi se pasa como argumento más de un archivo seguido del nombre de un
directorio (siempre que el nombre del directorio sea el último
argumento), cp copia los archivos en el directorio
especificado.
Si se proveen tres nombres de archivo, cp arroja un
error porque espera un nombre de directorio como último argumento.
OUTPUT
cp: target ‘morse.txt' is not a directoryListado recursivo y por tiempo
El comando ls -R enumera el contenido de los directorios
recursivamente, es decir, enumera sus subdirectorios, subdirectorios
secundarios, etc. en orden alfabético en cada nivel. El comando
ls -t enumera los contenidos de acuerdo a la fecha y hora
del último cambio, empezando por los archivos o directorios modificados
más recientemente. ¿En qué orden muestra los archivos el comando
ls -R -t?
El comando ls -R enumera los directorios recursivamente
en orden cronológico de cada nivel, y los archivos en cada directorio
también son desplegados en orden cronológico.
Creación de archivos de una manera diferente
Hemos visto cómo crear archivos de texto usando el editor
nano. Ahora, intenta el siguiente comando en tu directorio
personal:
¿Qué hizo el comando touch? Cuando abre su directorio de inicio con el explorador de archivos GUI, ¿aparece el archivo?
Utilice
ls -lpara inspeccionar los archivos. ¿Qué tan grande esmy_file.txt?¿En que circunstancias desearía crear un archivo de esta manera?
- El comando touch genera un nuevo archivo llamado “my_file.txt” en tu
directorio home. Si te encuentras en tu directorio
home, puedes observar el archivo recién creado
utilizando
lsen la terminal. También puedes visualizar “my_file.txt” en tu explorados de archivos GUI. - Cuando inspeccionas el archivo con “ls -l”, nota que el tamaño de “my_file.txt” es 0 kb. En otras palabras, no contiene dato alguno. Si abres “my_file.txt” en un editor de texto, aparecerá en blanco.
- Algunos programas no generan nuevos archivos de salida, pero requieren archivos en blanco que ya se hayan generado. Cuando uno de estos programas es ejecutado, automáticamente busca un archivo existente para llenarlo con su salida. El comando touch te permite generar eficientemente archivos en blanco para que este tipo de programas puedan usarlos.
Pasar a la carpeta actual
Después de ejecutar los siguientes comandos, Jamie se da cuenta de
que puso los archivos sucrose.dat ymaltose.dat
en la carpeta incorrecta:
BASH
$ ls -F
raw/ analyzed/
$ ls -F analyzed
fructose.dat glucose.dat maltose.dat sucrose.dat
$ cd raw/Rellena los espacios en blanco para mover estos archivos a la carpeta de trabajo (es decir, en la que ella está actualmente):
Utilizando rm con seguridad
¿Qué ocurre cuando escribimos
rm -i thesis/quotations.txt? ¿Por qué querríamos esta
protección cuando usamos rm?
La opción -i provocará que se pregunte antes de eliminar un elemento. La terminal de Unix no cuenta con una papelera de reciclaje, así que todos los archivos que sean eliminados desaparecerán para siempre. Por medio de la opción -i tienes la oportunidad de revisar que sólo estés eliminando los archivos que realmente deseas borrar.
Copiar una estructura de carpetas sin archivos
Estás iniciando un nuevo experimento y te gustaría duplicar la estructura de archivos que utilizaste para tu experimento anterior, sin los archivos de datos para que puedas añadir los nuevos datos.
Suponte que la estructura de archivos está en una carpeta llamada
‘2016-05-18-data’, que contiene un directorio data.
data a su vez contiene dos carpetas denominadas
raw y processed, que contienen archivos de
datos. El objetivo es copiar la estructura de archivos de la carpeta
2016-05-18-data en una carpeta llamada
2016-05-20-data y eliminar los archivos de datos de el
directorio que acabas de crear.
¿Cuál de los siguientes conjuntos de comandos lograrían este objetivo? ¿Qué harían los otros comandos?
BASH
$ cp -r 2016-05-18-data/ 2016-05-20-data/
$ rm 2016-05-20-data/data/raw/*
$ rm 2016-05-20-data/data/processed/*El primer grupo de comandos logra este objetivo. Primero se crea una
copia recursiva de la carpeta data. Después, dos comandos
rm eliminan todos los archivos en los directorios
especificados. La terminal interpreta el caracter especial
* para incluír todos los archivos y subdirectorios.
El segundo grupo de comandos está en el orden incorrecto: intenta borrar archivos que aún no han sido copiados, seguido del comando recursivo que los copiaría.
El tercer grupo de comandos podría lograr el objetivo deseado, pero de una forma muy poco eficiente: el primer comando copia el directorio de forma recursiva, pero el segundo comando borra de forma interactiva, requiriendo confirmación antes de borrar cada archivo y directorio.
Key Points
-
cp old newcopia un archivo. -
mkdir pathcrea un nuevo directorio. -
mv old newmueve (renombra) un archivo o directorio. -
rm pathelimina un archivo. - El uso de la tecla Control puede ser descrito de muchas maneras,
incluyendo
Ctrl-X,Control-Xy^ X. - El shell no tiene una papelera de reciclaje o bote de basura: una vez que algo se elimina, se borra completamente.
- Dependiendo del tipo de trabajo que se requiera, puede ser necesario utilizar un editor de textos más poderoso que Nano.
Content from Pipes y filtros
Last updated on 2023-04-24 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- ¿Cómo puedo combinar comandos existentes para hacer cosas nuevas?
Objectives
- Redireccionar la salida de un comando a un archivo.
- Procesar un archivo en lugar de la entrada de teclado mediante la redirección.
- Construir pipelines de comandos con dos o más etapas.
- Explicar lo que normalmente sucede si un programa o un pipeline no recibe ninguna entrada para procesar.
- Explicar las filosofía de Unix de ‘pequeñas piezas, libremente unidas’.
Ahora que ya sabemos algunos comandos básicos, podemos ver finalmente
la característica más poderosa de la terminal: la facilidad con la que
nos permite combinar los programas existentes de nuevas maneras.
Comenzaremos con un directorio llamado molecules que
contiene seis archivos que describen algunas moléculas orgánicas
simples. La extensión .pdb indica que estos archivos están
en formato Protein Data Bank, un formato de texto simple que especifica
el tipo y la posición de cada átomo en la molécula.
OUTPUT
cubane.pdb ethane.pdb methane.pdb
octane.pdb pentane.pdb propane.pdbEntra a ese directorio usando el comando cd y ejecuta el
comando wc *.pdb. wc es el comando “word
count”: cuenta el número de líneas, palabras y caracteres de un archivo.
El * en *.pdb coincide con cero o más
caracteres, por lo que la terminal convierte *.pdb en una
lista de todos los archivos .pdb en el directorio
actual:
OUTPUT
20 156 1158 cubane.pdb
12 84 622 ethane.pdb
9 57 422 methane.pdb
30 246 1828 octane.pdb
21 165 1226 pentane.pdb
15 111 825 propane.pdb
107 819 6081 totalCaracteres especiales
* Es un caracter especial o wild card.
Corresponde a cero o más caracteres, así que *.pdb coincide
conethane.pdb, propane.pdb, y cada archivo que
termina con ‘.pdb’. Por otro lado, p*.pdb sólo coincide con
pentane.pdb ypropane.pdb, porque la ‘p’ al
inicio hace coincidir los nombres de archivos que comienzan con la letra
‘p’.
? también es un caracter especial, pero sólo coincide
con un solo carácter. Esto significa que p?.pdb podría
coincidir con pi.pdb op5.pdb (si existieran en
el directorio molecules), pero nopropane.pdb.
Podemos usar cualquier número de caracteres especiales a la vez: por
ejemplo, p*.p?* coincide con cualquier cosa que comience
con una ‘p’ y termine con ‘.’, ‘p’, y al menos un carácter más (ya que
? tiene que coincidir con un carácter, y el final
* puede coincidir con cualquier número de caracteres). Por
lo tanto, p*.p?* coincidirá con
preferred.practice, e incluso p.pi (dado que
el primer * no coincide con ningún carácter), pero no
quality.practice (ya que no inicia con ‘p’) o
preferred.p (porque no hay al menos un carácter después de
‘.p’).
Cuando la terminal reconoce un caracter especial lo expande para
crear una lista de nombres de archivo coincidentes antes de
ejecutar el comando seleccionado. Como excepción, si una expresión con
caracteres especiales no coincide con algún archivo, la terminal pasará
la expresión como un parámetro al comando tal y como está escrita. Por
ejemplo, ejecutar ls *.pdf en el
directoriomolecules (que contiene sólo los archivos con
nombres que terminan con .pdb) da como resultado un mensaje
de error indicando que no hay ningún archivo llamado
* .pdf. Sin embargo, generalmente comandos como
wc yls ven las listas de nombres de archivo
que coinciden con estas expresiones, pero no los comodines por si solos.
Es la terminal, no los otros programas, la que se ocupa de expandir los
caracteres especiales, este es otro ejemplo de diseño ortogonal.
Usando caracteres especiales
En el directorio molecules, ¿qué variación del
comandols producirá esta salida?
ethane.pdb methane.pdb
ls *t*ane.pdbls *t?ne.*ls *t??ne.pdbls ethane.*
La solución es 3.
muestra todos los archivos que contienen cualquier número o combinación de caracteres seguidos de la letra
t, otro caracter único, y terminan conane.pdb. Esto incluyeoctane.pdbypentane.pdb.muestra todos los archivos que contienen cualquier número o combinación de caracteres,
t, otro caracter,ne., seguido de otro número o combinación de caracteres. Esto regresaríaoctane.pdbypentane.pdbpero nad que termine conthane.pdb.soluciona el problema de la opción 3 agregando dos caracteres entre
tyme. Esta es la opción correcta.sólo muestra archivos que comienzan con
ethane..
Si ejecutamos wc -l en lugar dewc, la
salida sólo muestra el número de líneas por archivo:
OUTPUT
20 cubane.pdb
12 ethane.pdb
9 methane.pdb
30 octane.pdb
21 pentane.pdb
15 propane.pdb
107 totalTambién podemos usar -w para obtener sólo el número de
palabras, o -c para obtener sólo el número de
caracteres.
¿Cuál de estos archivos es el más corto? Es una pregunta fácil de responder cuando sólo hay seis archivos, pero ¿y si hubiera 6,000? Nuestro primer paso hacia una solución es ejecutar el comando:
El símbolo “mayor que”, >, le dice a la terminal que
redireccione la salida del comando a un archivo en
lugar de imprimirlo en la pantalla. (Es por eso que no hay salida de
pantalla: en vez de mostrarlo, todo lo que wc imprime se ha
enviado al archivo lengths.txt.) Si no existe el archivo,
la terminal lo creará. Si el archivo existe, será sobrescrito
silenciosamente, lo que puede provocar pérdida de datos y, por lo tanto,
requiere cierta precaución. ls lengths.txt confirma que el
archivo existe:
OUTPUT
lengths.txtAhora podemos enviar el contenido de lengths.txt a la
pantalla usando cat lengths.txt. cat significa
“concatenate” (concatenar): imprime el contenido de los archivos uno
tras otro. En este caso sólo hay un archivo, así que cat
sólo nos muestra lo que éste contiene:
OUTPUT
20 cubane.pdb
12 ethane.pdb
9 methane.pdb
30 octane.pdb
21 pentane.pdb
15 propane.pdb
107 totalSalida Página por página
Continuaremos usando cat en esta lección, por
conveniencia y consistencia, pero tiene la desventaja de que siempre
vuelca todo el archivo en la pantalla. En la práctica es más útil el
comando less, que se utiliza como
$ less lengths.txt. Este comando muestra sólo el contenido
del archivo que cabe en una pantalla y luego se detiene. Puedes avanzar
a la siguiente pantalla presionando la barra espaciadora, o retroceder
presionando b. Para salir, pulsa q.
Ahora utilizemos el comando sort para ordenar el
contenido. También usaremos el indicador -n para
especificar que el tipo de orden que requerimos es numérico en lugar de
alfabético. Esto no cambia el archivo; sólo despliega el
resultado ordenado en la pantalla:
OUTPUT
9 methane.pdb
12 ethane.pdb
15 propane.pdb
20 cubane.pdb
21 pentane.pdb
30 octane.pdb
107 totalPodemos poner la lista de líneas ordenada en otro archivo temporal
llamado sorted-lengths.txt poniendo
> sorted-lengths.txt después del comando, así como
usamos > lengths.txt para poner la salida de
wc en lengths.txt. Una vez que hayamos hecho
eso, podemos ejecutar otro comando llamado head para
obtener las primeras líneas de sorted-lengths.txt:
OUTPUT
9 methane.pdbEl parámetro -n 1 con head indica que sólo
queremos la primera línea del archivo; -n 20 conseguirá las
primeras 20, y así sucesivamente. Dado que
sorted-lengths.txt contiene las longitudes de nuestros
archivos ordenados de menor a mayor, la salida de head debe
ser el archivo con menos líneas.
Si crees que es confuso, no estás solo: incluso una vez que entiendas
lo que wc,sort y head hacen,
todos esos archivos intermedios hacen difícil seguir el hilo de lo que
está pasando. Podemos hacerlo más fácil de entender ejecutando
sort y head juntos:
OUTPUT
9 methane.pdbLa barra vertical, |, entre los dos comandos se denomina
pipe (pronunciado paip). El pipe le
dice a la terminal que queremos usar la salida del comando a la
izquierda como entrada al comando de la derecha. La computadora puede
crear un archivo temporal si es necesario, copiar datos de un programa a
otro en la memoria, o cualquier otra cosa que sea necesaria; no es
necesario que lo entendamos para hacerlo funcionar.
Nada nos impide encadenar pipes consecutivamente.
Por ejemplo, puedes enviar la salida de wc directamente a
sort, y luego la salida resultante a head.
Así, primero usamos un pipe para enviar la salida de
wc a sort:
OUTPUT
9 methane.pdb
12 ethane.pdb
15 propane.pdb
20 cubane.pdb
21 pentane.pdb
30 octane.pdb
107 totalY ahora enviamos la salida de este pipe, a través de
otro pipe, a head, para que el
pipeline completo se convierta en:
OUTPUT
9 methane.pdbEsto es exactamente como un matemático anidando funciones como
log(3x) Y diciendo “el logaritmo de tres veces x”. En
nuestro caso, el cálculo es “cabeza de la lista ordenada del número de
líneas de *.pdb”.
Esto es lo que realmente sucede detrás de la terminal cuando creamos un pipe. Cuando una computadora ejecuta un programa (cualquier programa) crea un proceso en memoria para almacenar el software del programa y su estado actual. Cada proceso tiene un canal de entrada llamado entrada estándar. (Para este punto, puede sorprenderte que el nombre es tan memorable, pero no te preocupes, la mayoría de los programadores de Unix lo llaman “stdin”). Cada proceso también tiene un canal de salida predeterminado llamado salida estándar (o “stdout”). Un tercer canal de salida llamado error estándar (stderr) también existe. Este canal suele utilizarse para mensajes de error o de diagnóstico y permite al usuario canalizar la salida de un programa a otro mientras sigue recibiendo mensajes de error en el terminal.
La terminal es realmente otro programa. Bajo circunstancias normales, lo que ingresemos en el teclado se envía a la entrada estándar de la terminal, y lo que produce en la salida estándar se muestra en nuestra pantalla. Cuando le decimos a la terminal que ejecute un programa, ésta crea un nuevo proceso y envía temporalmente lo que tecleamos en nuestro teclado a la entrada estándar de ese proceso, y lo que el proceso envía a la salida estándar, la terminal lo envía a la pantalla.
Esto es lo que ocurre cuando ejecutamos
wc -l *.pdb > lengths.txt. La terminal comienza
diciéndole a la computadora que cree un nuevo proceso para ejecutar el
programa wc. Como hemos proporcionado algunos nombres de
archivo como parámetros, wc lee estos en vez de la entrada
estándar. Y puesto que hemos utilizado > para redirigir
la salida a un archivo, la terminal conecta la salida estándar del
proceso a ese archivo.
Si ejecutamos wc -l *.pdb | sort -n en su lugar, la
terminal crea dos procesos (uno para cada proceso en el
pipe) de modo que wc ysort
funcionan simultáneamente. La salida estándar de wc es
alimentada directamente a la entrada estándar de sort; ya
que no hay redirección con >, la salida de
sort va a la pantalla. Y si ejecutamos
wc -l * .pdb | sort -n | head -n 1, obtenemos tres procesos
con datos que fluyen de los archivos, a través de wc a
sort, de sort ahead y finalmente
a la pantalla.
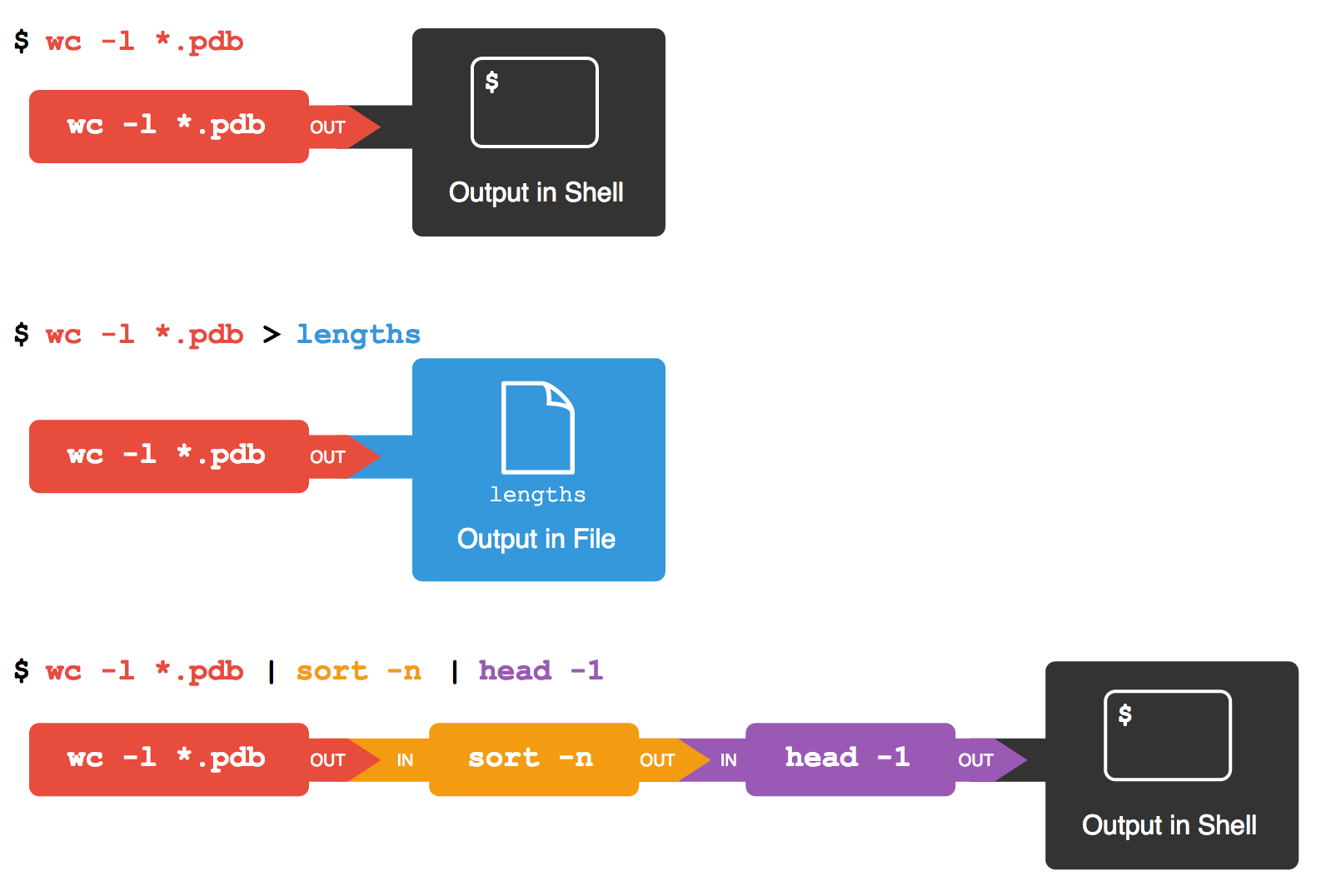
Esta sencilla idea es la razón por la cual Unix ha tenido tanto
éxito. En lugar de crear enormes programas que tratan de hacer muchas
cosas diferentes, los programadores de Unix se centran en crear muchas
herramientas simples que hacen bien su trabajo y son capaces de cooperar
entre sí. Este modelo de programación se llama “pipes y
filtros”. Ya hemos visto pipes; un
filtro es un programa como wc
osort que transforma una entrada en una salida. Casi todas
las herramientas estándar de Unix pueden funcionar de esta manera: a
menos que se les indique lo contrario, leen de entrada estándar, hacen
algo con lo que han leído, y escriben en la salida estándar.
La clave es que cualquier programa que lea líneas de texto de entrada estándar y escriba líneas de texto en la salida estándar puede combinarse con cualquier otro programa que se comporte de esta manera también. Puedes y debes escribir tus programas de esta manera para que tú y otras personas puedan poner esos programas en pipes y así multiplicar su poder.
Redireccionamiento de entrada
Además de usar > para redirigir la salida de un
programa, podemos usar < para redirigir su entrada, por
ejemplo, para leer un archivo en lugar de la entrada estándar. En lugar
de escribir wc ammonia.pdb, podríamos escribir
wc < ammonia.pdb. En el primer caso, wc
obtiene un parámetro de línea de comandos diciéndole qué archivo abrir.
En el segundo, wc no tiene ningun parámetro de la línea de
comandos, por lo que se lee desde la entrada estándar, pero hemos
indicado al shell que envíe el contenido de ammonia.pdb a
la entrada estándar de wc, por lo que el resultado de ambos
comandos es el mismo.
Pipeline de Nelle: Comprobación de archivos
Nelle ha procesado sus muestras en su máquina de ensayo, generando 17
archivos en el directorio north-pacific-gyre/2012-07-03
descrito anteriormente. Como un chequeo rápido, a partir de su
directorio de inicio, Nelle teclea:
La salida son 18 líneas que como estas:
OUTPUT
300 NENE01729A.txt
300 NENE01729B.txt
300 NENE01736A.txt
300 NENE01751A.txt
300 NENE01751B.txt
300 NENE01812A.txt
... ...Ahora escribe esto:
OUTPUT
240 NENE02018B.txt
300 NENE01729A.txt
300 NENE01729B.txt
300 NENE01736A.txt
300 NENE01751A.txtUps: uno de los archivos tiene 60 líneas menos que los otros. Cuando Nelle vuelve y lo revisa ve que hizo ese ensayo a las 8:00 un lunes por la mañana. Alguien probablemente usó la misma máquina ese fin de semana, y olvidó reiniciarla. Antes de volver a analizar esa muestra, decide comprobar si algunos archivos tienen demasiados datos:
OUTPUT
300 NENE02040B.txt
300 NENE02040Z.txt
300 NENE02043A.txt
300 NENE02043B.txt
5040 totalEsas cifras parecen buenas pero, ¿qué es esa ‘Z’ en la antepenúltima línea? todas sus muestras deben estar marcadas con “A” o “B”; por convención, su laboratorio utiliza ‘Z’ para indicar muestras con información que falta. Para encontrar a otros archivos como este, Nelle hace lo siguiente:
OUTPUT
NENE01971Z.txt NENE02040Z.txtComo esperaba, cuando comprueba el registro en su computadora
portátil, no hay profundidad registrada para ninguna de esas muestras.
Ya que es demasiado tarde para obtener la información de otra manera,
ella debe excluir esos dos archivos de su análisis. Podría simplemente
borrarlos usando rm, pero en realidad hay algunos análisis
que podría hacer más tarde, donde la profundidad no importa, por lo que,
en vez de borrarlos, sólo tendrá cuidado al seleccionar archivos
utilizando la expresión con caracteres especiales
*[AB].txt. Como siempre, el * coincide con
cualquier número de caracteres; la expresión [AB] coincide
con una ‘A’ o una ‘B’, por lo que coincide con los nombres de todos los
archivos de datos válidos que tiene.
¿Qué hace sort -n?
Si ejecutamos sort en este archivo:
10
2
19
22
6la salida es:
OUTPUT
10
19
2
22
6Si ejecutamos sort -n en la misma entrada, obtendremos
esto en su lugar:
OUTPUT
2
6
10
19
22Explique por qué -n tiene este efecto.
La opción -n indica un ordenamiento numérico, en lugar
de alfabético.
< se usa para redirigir la entrada a un comando.
En los dos ejemplos, la terminal regresa el número de líneas en la
entrada al comando wc. En el primer ejemplo, la entrada es
el archivo notes.txt y el nombre del archivo se menciona en
la salida del comando wc. En el segundo ejemplo, el
contenido del archivo notes.txt es redireccionado a la
entrada estándar. Es como si hubiéramos introducido el contenido del
archivo a mano. Por esto, el nombre del archivo no es especificado en la
salida, sólo el número de líneas. Inténtalo por tu cuenta.
BASH
$ wc -l
this
is
a test
Ctrl-D # Esto le indica a la terminal que has terminado de teclear la entrada.OUTPUT
3¿Qué significa
>>?Hemos visto el uso de
>pero hay un operador similar>>que funciona un poco distinto. Aprenderemos sobre la diferencia de estos comandos impriendo algunas cadenas de caracteres. Podemos usar el comandoechopara imprimir cadenas de caracteres, e.g.:
OUTPUT
El comando echo imprime el texto
Ahora prueba los comandos siguientes para revelar la diferencia entre los dos operadores.
¿Cuál es la diferencia entre:
Más información sobre caracteres especiales
Sam tiene un directorio que contiene datos de calibración, otros datos y descripciones de estos datos:
BASH
2015-10-23-calibration.txt
2015-10-23-dataset1.txt
2015-10-23-dataset2.txt
2015-10-23-dataset_overview.txt
2015-10-26-calibration.txt
2015-10-26-dataset1.txt
2015-10-26-dataset2.txt
2015-10-26-dataset_overview.txt
2015-11-23-calibration.txt
2015-11-23-dataset1.txt
2015-11-23-dataset2.txt
2015-11-23-dataset_overview.txtAntes de ir a otro viaje de campo, Sam quiere respaldar sus datos y enviar algunos datasets a su colega Bob. Sam utiliza los siguientes comandos para lograrlo:
BASH
$ cp *dataset* /backup/datasets
$ cp ____calibration____ /backup/calibration
$ cp 2015-____-____ ~/send_to_bob/all_november_files/
$ cp ____ ~/send_to_bob/all_datasets_created_on_a_23rd/Ayuda a Sam rellenando los espacios en blanco.
Uniendo comandos con pipes
En nuestro directorio actual, queremos encontrar los 3 archivos que tienen el menor número de líneas. ¿Cuál de los siguientes comandos funcionaría?
wc -l * > sort -n > head -n 3wc -l * | sort -n | head -n 1-3wc -l * | head -n 3 | sort -nwc -l * | sort -n | head -n 3
La solución es la opción 4. El caracter de pipe
| es usado para alimentar la entrada estándar de un proceso
con la salida estándar del anterior. > es utilizado para
redirigir la salida estándar a un archivo. ¡Inténtalo en el directorio
data-shell/molecules!
¿Por qué uniq sólo elimina
duplicados adyacentes?
El comando uniq elimina las líneas duplicadas adyacentes
de su entrada. Por ejemplo, el archivo
data-shell/salmon.txt contiene:
coho
coho
steelhead
coho
steelhead
steelheadEl comando uniq salmon.txt del directorio
data-shell/data produce:
OUTPUT
coho
steelhead
coho
steelhead¿Por qué crees que uniq sólo elimina líneas
adyacentes duplicadas? (Pista: piensa en datasets muy largos.) ¿Qué
otro comando podría combinarse con él en un pipe para
eliminar todas las líneas duplicadas?
Comprensión de la lectura de pipes
Un archivo llamado animals.txt (en el directorio
data-shell/data) contiene los siguientes datos:
2012-11-05,deer
2012-11-05,rabbit
2012-11-05,raccoon
2012-11-06,rabbit
2012-11-06,deer
2012-11-06,fox
2012-11-07,rabbit
2012-11-07,bear¿Qué texto pasa a través de cada uno de los pipes y qué incluye el redireccionamiento final en el siguiente pipeline?
Pista: construye el pipeline agregando un comando a la vez para comprobar tu respuesta.
Construcción de Pipes
Para el archivo animals.txt del ejercicio anterior, el
comando:
produce la siguiente salida:
OUTPUT
deer
rabbit
raccoon
rabbit
deer
fox
rabbit
bear¿Qué otro(s) comando(s) podría(n) agregarse a estos en un pipeline para encontrar qué animales contiene el archivo (sin nombres duplicados)?
Eliminación de archivos innecesarios
Suponte que deseas borrar tus archivos de datos procesados y sólo
conservar los archivos sin procesar y el script de
procesamiento para ahorrar espacio en disco. Los archivos sin procesar
terminan en .dat y los archivos procesados terminan en
.txt. ¿Cuál de las siguientes opciones eliminaría todos los
archivos de datos procesados, y nada más que los archivos de
datos procesados?
rm ?.txtrm *.txtrm * .txtrm *.*
- Esto eliminaría archivos con terminación
.txty nombres de un caracter. - Esta es la respuesta correcta.
- La terminal expandiría el
*para coincidir con todo el directorio actual, así que el comando intentaría eliminar todos los archivos, más un archivo adicional llamado.txt. - La terminal expandiría
*.*para coincidir con todos los archivos, independientemente de su terminación. Este comando eliminaría todos los archivos.
Expresiones con Caracteres Especiales
Las expresiones con caracteres especiales pueden llegar a ser muy
complejas, sin embargo a veces es posible escribirlas de forma que
utilicen una sintaxis muy sencilla y sean un poco más elocuentes.
Considera el directorio
data-shell/north-pacific-gyre/2012-07-03 : la expresión
*[AB].txt coincide con todos los archivos que terminan en
A.txt o B.txt. Imagina que ignoras esto.
¿Podrías hacer coincidir el mismo set de archivos con una expresión que incluya caracteres especiales, pero no
[]? Pista: Podrías necesitar más de una expresión.La expresión que encontraste y la expresión usada en la lección coinciden con el mismo grupo de archivos en el ejemplo. ¿Puedes identificar la ligera diferencia en la salida de ambos comandos?
¿Bajo qué circunstancias tu nueva expresión produciría un mensaje de error y la expresión original no?
¿Qué tubería?
El archivo data-shell/data/animals.txt contiene 586
líneas de datos en el siguiente formato:
OUTPUT
2012-11-05,deer
2012-11-05,rabbit
2012-11-05,raccoon
2012-11-06,rabbit
...Asumiendo que tu directorio actual sea data-shell/data/,
¿qué comando usarías para producir una tabla que muestre el recuento
total de cada tipo de animal en el archivo?
grep {deer, rabbit, raccoon, deer, fox, bear} animals.txt | wc -lsort animals.txt | uniq -csort -t, -k2,2 animals.txt | uniq -ccut -d, -f 2 animals.txt | uniq -ccut -d, -f 2 animals.txt | sort | uniq -ccut -d, -f 2 animals.txt | sort | uniq -c | wc -l
La opción 5 es la respuesta correcta. Si se te dificulta entender por
qué, intenta probar los comandos, o las subsecciones de los
pipelines (sólo asegúrate de estar en el directorio
data-shell/data).
Adición de datos
Considera el archivo animals.txt, utilizado en el
ejercicio anterior. Después de estos comandos, selecciona la respuesta
que describe el contenido del archivo animalsUpd.txt:
- Las tres primeras líneas de
animals.txt - Las dos últimas líneas de
animals.txt - Las tres primeras líneas y las dos últimas líneas de
animals.txt - La segunda y tercera líneas de
animals.txt
La opción 3 es la correcta. Para que la opción 1 fuera correcta
tendríamos que haber ejecutado sólo el comando head. Para
que la opción 2 fuera correcta tendríamos que haber ejecutado sólo el
comando tail. Para que la opción 4 fuera correcta
tendríamos que haber usado un pipe para enviar la
salida de head a tail -2 de esta forma:
head -3 animals.txt | tail -2 >> animalsUpd.txt
Key Points
-
catmuestra el contenido de sus entradas. -
headmuestra las primeras líneas de su entrada. -
tailmuestra las últimas líneas de su entrada. -
sortordena sus entradas. -
wccuenta líneas, palabras y caracteres en sus entradas. -
*coincide con cero o más caracteres en un nombre de archivo, por lo que*.txtcoincide con todos los archivos que terminan en.txt. -
?Coincide con un solo carácter en un nombre de archivo, así que?.txtcoincide cona.txtpero noany.txt. -
command > fileredirige la salida de un comando a un archivo. -
first | secondes un pipeline: la salida del primer comando se utiliza como entrada para el segundo. - La mejor manera de usar la terminal es utilizar pipes para combinar programas sencillos de propósito único (filtros).
Content from Bucles
Last updated on 2023-04-24 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- ¿Cómo puedo realizar las mismas acciones en varios archivos diferentes?
Objectives
- Escribir un bucle que aplique uno o más comandos por separado a cada archivo de un conjunto de archivos.
- Rastrear los valores tomados por una variable de bucle durante la ejecución del bucle.
- Explicar la diferencia entre el nombre de una variable y su valor.
- Explicar por qué los espacios y algunos caracteres de puntuación no deben usarse en nombres de archivo.
- Demostrar cómo ver qué comandos han sido ejecutados recientemente.
- Volver a ejecutar comandos ejecutados recientemente sin volver a escribirlos.
Los bucles (loops en inglés) son fundamentales para
mejorar la productividad a través de la automatización, ya que nos
permiten ejecutar comandos de forma repetitiva. Al igual que los
caracteres especiales y el autocompletado, el uso de bucles también
reduce la cantidad de tecleo (y los errores de escritura/dedo). Suponte
que tenemos varios cientos de archivos con datos genómicos denominados
basilisk.dat,unicorn.dat y así sucesivamente.
En este ejemplo, usaremos el directorio creatures que sólo
tiene dos archivos de ejemplo, pero los principios se pueden aplicar a
muchos más archivos a la vez. Nos gustaría modificar estos archivos,
pero también guardar una versión de los archivos originales, nombrando
las copias original-basilisk.dat
yoriginal-unicorn.dat. No podemos usar:
Porque se expandiría a:
Esto no respalda nuestros archivos, en su lugar obtenemos un error:
ERROR
cp: target `original-*.dat' is not a directoryEste problema surge cuando cp recibe más de dos
argumentos de entrada. Cuando esto sucede, espera que la última entrada
sea un directorio donde pueda copiar todos los archivos que se le
pasaron. Dado que no existe ningún directorio denominado
original-*.fasta en el directorio creatures,
se genera un error.
En cambio, podemos usar un bucle para ejecutar una operación a la vez sobre cada cosa en una lista. Aquí un ejemplo sencillo que muestra las tres primeras líneas de cada archivo de una sola vez:
OUTPUT
COMMON NAME: basilisk
CLASSIFICATION: basiliscus vulgaris
UPDATED: 1745-05-02
COMMON NAME: unicorn
CLASSIFICATION: equus monoceros
UPDATED: 1738-11-24Cuando la terminal reconoce la palabra clave for, sabe
que debe repetir un comando (o grupo de comandos) una vez para cada
elemento de una lista. Cada vez que el bucle se ejecuta (llamada
iteración), un elemento de la lista es asignado secuencialmente a una
variable, los comandos dentro del bucle se ejecutan
antes de pasar al siguiente elemento de la lista. Dentro del bucle,
pedimos el valor de la variable poniendo $ delante de ella.
El $ le dice al intérprete de la terminal que trate la
variable como un nombre de variable y substituya su
valor, en lugar de tratarlo como texto o como un comando externo.
En este ejemplo, la lista tiene dos nombres de archivo:
basilisk.dat yunicorn.dat. Cada vez que el
bucle se itera, asignará un nombre de archivo a la variable
filename y ejecutará el comando head. La
primera vez en el bucle, $filename
esbasilisk.dat. El intérprete ejecuta el comando
head en basilisk.dat, e imprime las primeras
tres líneas de basilisk.dat. Para la segunda iteración,
$filename se convierte en unicorn.dat. Esta
vez, la terminal ejecuta head enunicorn.dat e
imprime las tres primeras líneas de unicorn.dat. Dado que
la lista era sólo de dos elementos, la terminal sale del bucle
for.
Cuando se utilizan variables, también es posible poner sus nombres en
llaves para delimitar claramente el nombre de la variable:
$filename es equivalente a${filename}, pero es
diferente de ${file}name. Puede ser que encuentres esta
notación en programas escritos por otras personas.
Siga las instrucciones
El prompt de la terminal cambia de $ a
> y de nuevo a $ conforme escribimos
nuestro bucle. El segundo prompt, >, es
diferente para recordarnos que todavía no hemos terminado de escribir un
comando completo. Un punto y coma, ;, se puede utilizar
para separar dos comandos escritos en una sola línea.
Los mismos símbolos, diferentes significados
Aquí vemos > siendo utilizado como un prompt de la
terminal, mientras que > también se utiliza para
redirigir la salida de un comando. De forma similar, $ se
utiliza como prompt de la terminal, pero como vimos antes, también se
utiliza para pedir que la terminal obtenga el valor de una variable.
Si la terminal imprime > o $
entonces espera que escribas algo, y el símbolo es un prompt.
Si tú escribes > o $, es una
instrucción de ti para la terminal indicándole redirigir la salida o
obtener el valor de una variable.
Hemos llamado a la variable en este bucle filename con
el fin de hacer su propósito más claro para los lectores humanos. A la
terminal no le importa el nombre de la variable; si escribimos este
bucle como:
or:
Funcionaría exactamente de la misma manera. No lo hagas así.
Los programas sólo son útiles si la gente puede entenderlos, nombres
crípticos (como x) o nombres engañosos
(comotemperature) aumentan las probabilidades de que el
programa no haga lo que sus lectores piensan que hace.
He aquí un bucle un poco más complicado:
La terminal comienza expandiendo *.dat para crear la
lista de archivos que procesará. Después de esto, el cuerpo del
bucle ejecuta dos comandos para cada uno de esos archivos. El
primero, echo, simplemente imprime sus parámetros de línea
de comandos a la salida estándar. Por ejemplo:
regresa:
OUTPUT
hello thereEn este caso, ya que la terminal expande $filename para
que sea el nombre de un archivo, echo $filename sólo
imprime el nombre del archivo. Ten en cuenta que no podemos escribir
esto como:
porque entonces la primera vez a través del bucle, cuando
$filename se expande a basilisk.dat, la
terminal intentará ejecutar basilisk.dat como un programa.
Finalmente, la combinación head y tail
selecciona las líneas 81-100 de cualquier archivo que se esté procesando
(suponiendo que el archivo tiene al menos 100 líneas).
Espacios en los nombres
El espacio en blanco se utiliza para separar los elementos de la lista que vamos a usar en el bucle. Si en la lista tenemos elementos con espacios en blanco necesitamos entrecomillar esos elementos y nuestra variable al usarlo. Supongamos que nuestros archivos de datos se llaman:
red dragon.dat
purple unicorn.datNecesitamos usar
BASH
for filename in "red dragon.dat" "purple unicorn.dat"
do
head -n 100 "$filename" | tail -n 20
doneEs más sencillo simplemente evitar el uso de espacios en blanco (u otros caracteres especiales) en los nombres de archivo.
Los archivos mencionados no existen, si corremos el código del último
ejemplo, el comando head será incapaz de encontrarlos, sin
embargo el mensaje de error regresará el nombre de los archivos que
espera:
OUTPUT
head: cannot open ‘red dragon.dat' for reading: No such file or directory
head: cannot open ‘purple unicorn.dat' for reading: No such file or directoryIntenta remover las comillas en $filename en el bucle
anterior para observar el efecto de las comillas en los espacios en
blanco:
OUTPUT
head: cannot open ‘red' for reading: No such file or directory
head: cannot open ‘dragon.dat' for reading: No such file or directory
head: cannot open ‘purple' for reading: No such file or directory
head: cannot open ‘unicorn.dat' for reading: No such file or directoryVolviendo a nuestro problema original de copia de archivos, Podemos resolverlo usando este bucle:
Este bucle ejecuta el comando cp una vez para cada
nombre de archivo. La primera vez, cuando $filename se
convierte en basilisk.dat, la terminal ejecuta:
La segunda vez, el comando es:
Como el comando cp no produce una salida normalmente, es
difícil verificar que el bucle está funcionando de forma correcta. Al
antecederle echo es posibe ver cada comando como
sería ejecutado. El siguiente diagrama muestra lo que sucede
cuando el código modificado es ejecutado, y demuestra cómo el uso de
echo es una práctica útil.

Pipeline de Nelle: Procesando Archivos
Nelle ahora está lista para procesar sus archivos de datos. Dado que todavía está aprendiendo cómo utilizar la terminal, decide construir los comandos requeridos en etapas. Su primer paso es asegurarse de que puede seleccionar los archivos correctos (recuerda, aquellos cuyos nombres terminan en ‘A’ o ‘B’, en lugar de ‘Z’). Posicionada en su directorio home, Nelle teclea:
BASH
$ cd north-pacific-gyre/2012-07-03
$ for datafile in NENE*[AB].txt
> do
> echo $datafile
> doneOUTPUT
NENE01729A.txt
NENE01729B.txt
NENE01736A.txt
...
NENE02043A.txt
NENE02043B.txtSu siguiente paso es decidir cómo llamar a los archivos que creará el
programa de análisis goostats. Prefijar el nombre de cada
archivo de entrada con “stats” parece simple, así que modifica su bucle
para hacer eso:
OUTPUT
NENE01729A.txt stats-NENE01729A.txt
NENE01729B.txt stats-NENE01729B.txt
NENE01736A.txt stats-NENE01736A.txt
...
NENE02043A.txt stats-NENE02043A.txt
NENE02043B.txt stats-NENE02043B.txtElla todavía no ha ejecutado goostats, pero ahora está
segura de que puede seleccionar los archivos correctos y generar los
nombres de archivo de salida correctos.
Escribir comandos una y otra vez es cada vez más tedioso, y a Nelle le preocupa cometer errores, así que en lugar de volver a crear su bucle, presiona la flecha hacia arriba. En respuesta, la terminal vuelve a mostrar el bucle completo en una línea (usando puntos y comas para separar las piezas):
Utilizando la tecla de flecha izquierda, Nelle realiza una copia de
seguridad y cambia el comando echo a
bash goostats:
Cuando presiona Enter, la terminal ejecuta el comando modificado. Sin
embargo, nada parece suceder porque no hay salida. Después de un
momento, Nelle se da cuenta de que, ya que su script no
imprime nada a la pantalla, no tiene ni idea de si está funcionando, y
mucho menos con qué rapidez. Mata el comando de ejecución escribiendo
Ctrl-C, e utiliza la flecha hacia arriba para repetir el
comando, y lo edita para que se vea así:
BASH
$ for datafile in NENE*[AB].txt; do echo $datafile; bash goostats $datafile stats-$datafile; donePrincipio y Fin
Podemos pasar al principio de una línea en la terminal escribiendo
Ctrl-A y al final usando Ctrl-E.
Ahora, cuando ejecuta su programa, produce una línea de salida cada cinco segundos aproximadamente:
OUTPUT
NENE01729A.txt
NENE01729B.txt
NENE01736A.txt
...1518 veces 5 segundos, dividido entre 60, le dice que su
script tomará alrededor de dos horas en terminar de
analizar todos los archivos. Como un chequeo final, abre otra ventana de
terminal, entra en north-pacific-gyre/2012-07-03, e utiliza
cat stats-NENE01729B.txt para examinar uno de los archivos
de salida. Se ve bien, así que decide tomarse un café y ponerse al día
con su lectura.
Aquellos que conocen la historia pueden elegir repetirla
Otra forma de repetir el trabajo anterior es usar el comando
history para obtener una lista de los últimos cientos de
comandos que se han ejecutado, y usar !123 (donde” 123 “es
reemplazado por el número de comando) para repetir uno de esos comandos.
Por ejemplo, si Nelle escribe esto:
OUTPUT
456 ls -l NENE0*.txt
457 rm stats-NENE01729B.txt.txt
458 bash goostats NENE01729B.txt stats-NENE01729B.txt
459 ls -l NENE0*.txt
460 historyEntonces puede volver a ejecutar goostats
enNENE01729B.txt simplemente escribiendo
!458.
Otros comandos del historial
Existen otros comandos de acceso directo para acceder al historial:
-
Ctrl-Rpermite buscar en el historial en un modo denominado “búsqueda reversa” (“reverse-i-search” en inglés), que permite buscar el comando más reciente en tu historial que coincide con el texto que introduzcas a continuación. PresionarCtrl-Runa o más veces adicionales permite buscar coincidencias más antiguas. -
!!recupera el comando anterior inmediato (puedes ser que esto te parezca más conveniente que usar la flecha hacia arriba). -
!$recupera la última palabra del último comando. Esto es más útil de lo que pensarías: después debash goostats NENE01729B.txt stats-NENE01729B.txt, puedes teclearless !$para ver el archivoNENE01729B.txt, que es más rápido que utilizar la flecha hacia arriba y editar el comando.
Variables en bucles
En el directorio data-shell/molecules, ls
regresa la siguiente salida:
OUTPUT
cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb¿Cuál es la salida del siguiente código?:
Ahora, ¿cuál es la salida de este código?:
¿Por qué estos dos bucles dan resultados diferentes?
El primer bloque de código regresa la misma salida en cada iteración
del bucle. La terminal expande el caracter especial *.pdb
en el cuerpo del bucle (y al principio del mismo) para coincidir con
todos los archivos que terminan en .pdb, y los enumera
utilizando ls. El bucel expandido se vería así:
BASH
for datafile in cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb
do
ls cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb
doneOUTPUT
cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb
cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb
cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb
cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb
cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdb
cubane.pdb ethane.pdb methane.pdb octane.pdb pentane.pdb propane.pdbEl segundo bloque de código enumera a un archivo distinto en cada
iteración. El valor de la variable datafile es evaluado
usando $datafile y después enumerado usando
ls.
OUTPUT
cubane.pdb
ethane.pdb
methane.pdb
octane.pdb
pentane.pdb
propane.pdbGuardar en un archivo dentro de un bucle - Primera parte
En el mismo directorio, ¿cuál es el efecto de este bucle?
- Imprime
cubane.pdb,ethane.pdb,methane.pdb,octane.pdb,pentane.pdbypropane.pdb, y el texto depropane.pdbse guarda en un archivo llamadoalkanes.pdb. - Imprime
cubane.pdb,ethane.pdb,methane.pdb, y concatena el texto de los tres archivos en un archivo llamadoalkanes.pdb. - Imprime
cubane.pdb,ethane.pdb,methane.pdb,octane.pdbypentane.pdb, y guarda el texto depropane.pdben un archivo llamadoalkanes.pdb. - Ninguna de las anteriores.
- El texto de cada archivo se escribe (uno a la vez) en
alkanes.pdb. Sin embargo, el archivo se sobrescribe en cada iteración del bucle, por lo que el contenido final dealkanes.pdbes sólo el texto proveniente depropane.pdb.
Guardar en un archivo en un bucle - Segunda parte
En el mismo directorio, ¿cuál sería la salida del siguiente bucle?
- Todo el texto de
cubane.pdb,ethane.pdb,methane.pdb,octane.pdbypentane.pdbsería concatenado y guardado en un archivo llamadoall.pdb. - El texto de
ethane.pdbse guardará en un archivo llamadoall.pdb. - Todo el texto de
cubane.pdb,ethane.pdb,methane.pdb,octane.pdb,pentane.pdbypropane.pdbsería concatenado y guardado en un archivo llamadoall.pdb. - Todo el texto de
cubane.pdb,ethane.pdb,methane.pdb,octane.pdb,pentane.pdbypropane.pdbse imprimirá en pantalla y será salvado en un archivo llamadoall.pdb.
La opción correcta es 3. >> concatena en un
archivo, en lugar de sobrescribirlo con la salida del comando. Dado que
la salida del comando cat ha sido redirigida, nada se
imprime en pantalla.
Limitación de conjuntos de archivos
La respuesta correcta es 4. * coincide con cero o más
caracteres, así que cualquier nombre que comience con la letra c,
seguida de cero o más caracteres, coincidirá con el comando
Limitación de conjuntos de archivos (continued)
La respuesta correcta es 4. * coincide con cero o más
caracteres, por lo que la expresión *c* coincidirá con un
nombre de archivo con cero o más caracteres antes de la letra c, y cero
o más caracteres después de la letra c.
Haciendo una ejecución “en seco” (dry-run)
Un bucle es una forma de hacer muchas cosas a la vez, o de cometer
muchos errores a la vez si se diseña de forma incorrecta. Una manera de
comprobar lo que un bucle hará es usar el comando
echo. En lugar de ejecutar los comandos, los mostrará en
pantalla.
Supongamos que queremos obtener una vista previa de los comandos que ejecutará el siguiente bucle, sin ejecutarlos realmente:
¿Cuál es la diferencia entre los dos bucles abajo, y cuál deberíamos usar?
La versión que querríamos utilizar es la 2. Esta versión imprime en
pantalla todo lo entrecomillado, expandiendo la variable del bucle
porque incluye el signo $ como prefijo.
La versión 1 redirige la salida del comando
echo analyze $file a un archivo,
analyzed-$file. Es decir, se genera una serie de archivos:
analyzed-cubane.pdb, analyzed-ethane.pdb,
etc.
Prueba ambas versiones en tu terminal para ver la salida. Asegúrate
de abrir los archivos analyzed-*.pdb para ver su
contenido.
Bucles anidado
Suponte que queremos configurar una estructura de directorios para organizar algunos experimentos que miden constantes de velocidad de reacción que involucran distintos compuestos y distintas temperaturas. ¿Cuál sería el resultado del siguiente código?:
Tenemos un bucle anidado, es decir, un bucle dentro de otro bucle:
para cada specie del bucle exterior, el bucle interior (el
bucle anidado) itera sobre la lista de temperaturas y crea un nuevo
directorio para cada combinación.
¡Intenta ejecutar el código para descubrir qué directorio se crean!
Key Points
- Un bucle
forrepite comandos una vez para cada elemento de una lista. - Cada bucle
fornecesita una variable para referirse al elemento en el que está trabajando actualmente. - Uso de
$namepara expandir una variable (es decir, obtener su valor). También se puede usar${name}. - No utilizar espacios, comillas o caracteres especiales como ‘*’ o ‘?’ en nombres de directorios, ya que complica la expansión de variables.
- Proporcionar a los archivos nombres coherentes que sean fáciles de combinar con los caracteres especiales para facilitar la selección de los bucles.
- Utilizar la tecla de flecha hacia arriba para desplazarse por los comandos anteriores para editarlos y repetirlos.
- Usar
Ctrl-Rpara buscar a través de los comandos previamente introducidos. - Usar
historypara mostrar comandos recientes, y!numberpara repetir un comando por número.
Content from Scripts de la terminal
Last updated on 2023-04-24 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- ¿Cómo puedo guardar y reutilizar comandos?
Objectives
- Escriba un script de la terminal que ejecute un comando o una serie de comandos para un conjunto fijo de archivos.
- Ejecutar un script de la terminal desde la línea de comandos.
- Escribir un script de la terminal que opere sobre un conjunto de archivos definidos por el usuario en línea de comandos.
- Crear pipelines que incluyan script de la terminal que tú y otros hayan escrito.
Finalmente estamos listos para ver lo que hace que la terminal sea un entorno de programación tan potente. Vamos a tomar los comandos que repetimos con frecuencia y los vamos a guardar en archivos de modo que podemos volver a ejecutar todas esas operaciones más tarde escribiendo un sólo comando. Por razones históricas, a un conjunto de comandos guardados en un archivo se le llama un script de la terminal, pero no se equivoquen: estos son en realidad pequeños programas.
Comencemos por volver a molecules/ creando un nuevo
archivo, middle.sh, que se convertirá en nuestro
script de la terminal:
El comando nano middle.sh abre el archivo
middle.sh dentro del editor de texto “nano” (que se ejecuta
dentro de la terminal). Si el archivo no existe, se creará. Podemos usar
el editor de texto para editar directamente el archivo - simplemente
insertaremos la siguiente línea:
Esta es una variación del pipe que construimos
anteriormente: selecciona las líneas 11-15 del archivo
octane.pdb. Recuerda, no lo estamos ejecutando
como un comando todavía: sólo estamos poniendo los comandos en un
archivo.
A continuación, guardamos el archivo (Ctrl-O en nano), y
salimos del editor de texto (Ctrl-X en nano). Comprueba que
el directorio molecules ahora contiene un archivo llamado
middle.sh.
Una vez que hayamos guardado el archivo, podemos pedirle a la
terminal que ejecute los comandos que contiene. Nuestra terminal se
llama bash, por lo que ejecutamos el siguiente comando:
OUTPUT
ATOM 9 H 1 -4.502 0.681 0.785 1.00 0.00
ATOM 10 H 1 -5.254 -0.243 -0.537 1.00 0.00
ATOM 11 H 1 -4.357 1.252 -0.895 1.00 0.00
ATOM 12 H 1 -3.009 -0.741 -1.467 1.00 0.00
ATOM 13 H 1 -3.172 -1.337 0.206 1.00 0.00Efectivamente, la salida de nuestro script es exactamente lo que obtendríamos si ejecutamos ese pipeline directamente en la terminal.
Texto vs. Lo que sea
Por lo general llamamos a programas como Microsoft Word o LibreOffice
Writer “editores de texto”, pero tenemos que ser un poco más cuidadosos
cuando se trata de programación. De forma predeterminada, Microsoft Word
utiliza archivos .docx para almacenar no sólo texto, sino también
información de formato sobre fuentes, encabezados, etcétera. Esta
información adicional no se almacena como caracteres y no es comprendida
por herramientas como head: los comandos esperan que los
archivos de entrada contengan únicamente letras, dígitos y puntuación en
un teclado de computadora estándar. Por lo tanto, al editar programas,
debemos utilizar un editor de texto sin formatos o tener cuidado de
guardar nuestros archivos como texto sin formato.
¿Qué pasa si queremos seleccionar líneas de un archivo arbitrario?
Podríamos editar middle.sh cada vez para cambiar el nombre
de archivo, pero eso probablemente llevaría más tiempo que simplemente
volver a escribir el comando. En cambio, editemos middle.sh
y hagamos que sea más versátil:
Ahora, dentro de “nano”, reemplaza el texto octane.pdb
con la variable especial denominada $1:
Dentro de un script de la terminal,$1
significa “el primer nombre de archivo (u otro parámetro) en la línea de
comandos”. Ahora podemos ejecutar nuestro script de
esta manera:
OUTPUT
ATOM 9 H 1 -4.502 0.681 0.785 1.00 0.00
ATOM 10 H 1 -5.254 -0.243 -0.537 1.00 0.00
ATOM 11 H 1 -4.357 1.252 -0.895 1.00 0.00
ATOM 12 H 1 -3.009 -0.741 -1.467 1.00 0.00
ATOM 13 H 1 -3.172 -1.337 0.206 1.00 0.00o con un archivo diferente:
OUTPUT
ATOM 9 H 1 1.324 0.350 -1.332 1.00 0.00
ATOM 10 H 1 1.271 1.378 0.122 1.00 0.00
ATOM 11 H 1 -0.074 -0.384 1.288 1.00 0.00
ATOM 12 H 1 -0.048 -1.362 -0.205 1.00 0.00
ATOM 13 H 1 -1.183 0.500 -1.412 1.00 0.00Comillas dobles alrededor de parámetros
Por la misma razón que ponemos la variable del bucle dentro de
comillas dobles, cuando el nombre de archivo contenga espacios, rodeamos
$1 con comillas dobles.
Aún así necesitamos editar middle.sh cada vez que
queramos ajustar el rango de líneas. Vamos a arreglar esto usando las
variables especiales $2 y$3 para el número de
líneas que se pasarán respectivamente a head y
tail:
OUTPUT
head -n "$2" "$1" | tail -n "$3"Ahora podemos ejecutar:
OUTPUT
ATOM 9 H 1 1.324 0.350 -1.332 1.00 0.00
ATOM 10 H 1 1.271 1.378 0.122 1.00 0.00
ATOM 11 H 1 -0.074 -0.384 1.288 1.00 0.00
ATOM 12 H 1 -0.048 -1.362 -0.205 1.00 0.00
ATOM 13 H 1 -1.183 0.500 -1.412 1.00 0.00Cambiando los parámetros de nuestra línea de comando, podemos cambiar el comportamiento del script:
OUTPUT
ATOM 14 H 1 -1.259 1.420 0.112 1.00 0.00
ATOM 15 H 1 -2.608 -0.407 1.130 1.00 0.00
ATOM 16 H 1 -2.540 -1.303 -0.404 1.00 0.00
ATOM 17 H 1 -3.393 0.254 -0.321 1.00 0.00
TER 18 1Esto funciona, pero a la siguiente persona que use
middle.sh se le puede dificultar ver lo que hace. Podemos
mejorar nuestro script agregando algunos
comentarios en la parte superior:
OUTPUT
# Select lines from the middle of a file.
# Usage: bash middle.sh filename end_line num_lines
head -n "$2" "$1" | tail -n "$3"Un comentario comienza con un caracter # y se ejecuta
hasta el final de la línea. La computadora ignora los comentarios, pero
son invaluables para ayudar a la gente (incluyéndote a ti en un futuro)
a entender y usar scripts. La única advertencia es que
cada vez que modifiques un script, debes comprobar que
el comentario siga siendo preciso: Una explicación que envía al lector
en la dirección equivocada es peor que ninguna.
¿Qué sucede si queremos procesar muchos archivos en un solo
pipeline? Por ejemplo, si queremos ordenar nuestros
archivos .pdb por longitud, deberíamos escribir:
dado que wc -l lista el número de líneas en los archivos
(recuerda que wc significa ‘word count’, y si agregas el
-l significa ‘contar líneas’) y sort -n ordena
numéricamente. Podríamos poner esto en un archivo, pero entonces sólo
podría ordenar una lista de archivos .pdb en el directorio
actual. Si queremos ser capaces de obtener una lista ordenada de otros
tipos de archivos, necesitamos una manera de conseguir estos nombres en
el script. No podemos usar $1,
$2, y así sucesivamente porque no sabemos cuántos archivos
hay. En su lugar, utilizamos la variable especial $@, lo
que significa, “Todos los parámetros de la línea de comandos para el
script”. También debemos poner $@ dentro
de comillas dobles para el caso de parámetros que contienen espacios
("$@" es equivalente a "$1" "$2"
…). He aquí un ejemplo:
OUTPUT
# Sort filenames by their length.
# Usage: bash sorted.sh one_or_more_filenames
wc -l "$@" | sort -nOUTPUT
9 methane.pdb
12 ethane.pdb
15 propane.pdb
20 cubane.pdb
21 pentane.pdb
30 octane.pdb
163 ../creatures/basilisk.dat
163 ../creatures/unicorn.dat¿Por qué no está haciendo nada?
¿Qué pasa si se supone que un script procesa un grupo de archivos, pero nosotros no le damos ningún nombre de archivo? Por ejemplo, ¿qué pasa si escribimos?:
pero sin agregar *.dat (o cualquier otra cosa)? En este
caso, $@ se expande a nada en absoluto, por lo que el
pipeline dentro del script es
efectivamente:
Dado que no tiene ningún nombre de archivo, wc supone
que debe procesar entrada estándar, por lo que sólo se sienta allí y
espera a que le demos algunos datos de forma interactiva. Desde el
exterior, sin embargo, todo lo que vemos es que el programa está
estático: el guión no parece hacer nada.
Supongamos que acabamos de ejecutar una serie de comandos que hicieron algo útil - por ejemplo, crearon un gráfico que nos gustaría utilizar en un documento. Nos gustaría poder volver a hacer el gráfico más tarde si es necesario, por lo que queremos guardar los comandos en un archivo. En lugar de escribirlos de nuevo (y potencialmente equivocarse) podemos hacer esto:
El archivo redo-figure-3.sh ahora contiene:
297 bash goostats -r NENE01729B.txt stats-NENE01729B.txt
298 bash goodiff stats-NENE01729B.txt /data/validated/01729.txt > 01729-differences.txt
299 cut -d ',' -f 2-3 01729-differences.txt > 01729-time-series.txt
300 ygraph --format scatter --color bw --borders none 01729-time-series.txt figure-3.png
301 history | tail -n 5 > redo-figure-3.shDespués de un poco de trabajo en un editor para eliminar los números
de serie en los comandos, y eliminar la línea final donde llamamos el
comando history, tenemos un registro completamente preciso
de cómo creamos dicha figura.
En la práctica, la mayoría de las personas desarrollan
scripts de la terminal ejecutando comandos en el prompt
de dicha terminal varias veces para asegurarse de que están haciendo las
cosas bien, y a continuación los guardan en un archivo para su
reutilización. Este estilo de trabajo permite a la gente replicar lo que
descubre sobre sus datos y su flujo de trabajo con una llamada a
history y editando para limpiar la salida pueden guardarlo
como un script de la terminal.
El pipeline de Nelle: Creando un script
El supervisor de Nelle insistió en que todos sus análisis deben ser
reproducibles. Nelle se da cuenta que debería haber proporcionado un par
de parámetros adicionales a goostats cuando procesó sus
archivos. Esto podría haber sido un desastre si hubiera hecho todo el
análisis a mano, pero gracias a los bucles for, sólo le
tomará un par de horas para volver a realizar el análisis. La forma más
fácil de capturar todos los pasos es en un script. Ella
ejecuta el editor y escribe lo siguiente:
BASH
# Calculate reduced stats for data files.
for datafile in "$@"
do
echo $datafile
bash goostats $datafile stats-$datafile
doneGuarda esto en un archivo llamado do-stats.sh para que
ahora pueda volver a hacer la primera etapa de su análisis
escribiendo:
Ella también puede hacer esto:
de modo que el output es sólo el número de archivos procesados en lugar de los nombres de los archivos que se procesaron.
Una cosa a tener en cuenta sobre el script de Nelle es que permite que la persona que lo ejecuta decida que archivos procesar. Podría haberlo escrito así:
BASH
# Calculate stats for Site A and Site B data files.
for datafile in NENE*[AB].txt
do
echo $datafile
bash goostats $datafile stats-$datafile
doneLa ventaja es que esto siempre selecciona los archivos correctos:
Ella no tiene que recordar excluir los archivos ‘Z’. La desventaja es
que siempre selecciona esos archivos - ella no puede ejecutarlo
en todos los archivos (incluidos los archivos ‘Z’), o en los archivos
‘G’ o ‘H’ que sus colegas de la Antártida están produciendo, sin editar
el script manualmente. Si quisiera ser más aventurera,
Nelle podría modificar su script para verificar los
parámetros en línea de comandos, y utilizar NENE*[AB].txt
si no se ha proporcionado ninguno. Por supuesto, esto introduce otro
equilibrio entre flexibilidad y complejidad.
Variables en los scripts de la terminal
En el directorio molecules, imagina que tienes un
script de la terminal llamado script.sh
que contiene los siguientes comandos:
Mientras estés en el directorio molecules, escribe el
siguiente comando:
¿Cuál de los siguientes resultados esperarías ver?
- Todas las líneas entre la primera y la última línea de cada archivo
que terminan en
.pdben el directoriomolecules. - La primera y la última línea de cada archivo que termina en
.pdben el directoriomolecules. - La primera y la última línea de cada archivo en el directorio
molecules. - Un error debido a las comillas alrededor de
*.pdb.
La respuesta correcta es la 2. Las variables $1,
$2 y $3 representan los argumentos para el
script, tal que los comandos ejecutados son:
BASH
$ head -n 1 cubane.pdb ethan ee.pdb octane.pdb pentane.pdb propane.pdb
$ tail -n 1 cubane.pdb ethane.pdb octane.pdb pentane.pdb propane.pdbLa terminal no expande ‘* .pdb’ porque está rodeado por comillas. El primer parámetro del script es ‘*.pdb’, que se expande dentro del script desde el principio al final.
Listando especies únicas
Leah tiene varios cientos de archivos de datos, cada uno de los cuales tiene el siguiente formato :
2013-11-05,deer,5
2013-11-05,rabbit,22
2013-11-05,raccoon,7
2013-11-06,rabbit,19
2013-11-06,deer,2
2013-11-06,fox,1
2013-11-07,rabbit,18
2013-11-07,bear,1Un ejemplo de este tipo de archivo se puede ver en data-shell/data/animal-counts/animals.txt.
Escribe un script de la terminal llamado
species.sh que tome cualquier número de nombres de archivos
como parámetros de línea de comandos, y utilice cut,
sort y uniq para mostrar una lista de las
especies únicas que aparecen en cada uno de esos archivos por
separado.
# El script para encontrar especies unicas en archivos .csv en donde "species" es la segunda data field
# Este script acepta cualquier número de nombres de archivos como argumentos de la línea de comando.
# Bucle loop
for file in $@
do
echo "Unique species in $file:"
# Extraer nombres de especies
cut -d , -f 2 $file | sort | uniq
doneEncuentre el archivo más largo con una extensión determinada
Escribe un script de la terminal llamado
longest.sh que tome el nombre de un directorio y una
extensión de nombre de archivo como sus parámetros, e imprima el nombre
del archivo con más líneas en ese directorio con esa extensión. Por
ejemplo:
Mostraría el nombre del archivo .pdb
en/tmp/data que tenga más líneas.
¿Por qué grabar los comandos en el historial antes de ejecutarlos?
Si ejecutas el comando:
El último comando del archivo es el mismo comando
history, es decir, la terminal ha añadido
history al registro de comandos antes de ejecutarlo. De
hecho, la terminal siempre agrega comandos al registro antes de
ejecutarlos. ¿Por qué crees que hace esto?
Si un comando hace que algo se cuelgue, podría ser útil saber cuál era ese comando para saber cuál fue el problema. Si el comando sólo se registra después de ejecutarlo, no tendríamos un registro del último comando ejecutado en caso de un bloqueo.
Script de lectura y comprensión
Considera el directorio data-shell/molecules una vez más. Este
contiene una cantidad de archivos .pdb además de otro archivo que hayas
creado. Explica, para los siguientes tres ejemplos, que hace el
script llamado example.sh cuando lo ejecutas como
bash example.sh *.pdb:
El script 1 mostrará una lista de todos los archivos que contienen un punto en su nombre.
El script 2 mostrará el contenido de los primeros 3 archivos que coinciden con la extensión del archivo. La terminal expande el caracter especial antes de pasar los argumentos al script example.sh.
El script 3 mostrará todos los parámetros del script (es decir, todos los archivos .pdb), seguido de .pdb. cubane.pdb etano.pdb metano.pdb octano.pdb pentano.pdb propano.pdb.pdb
Depuración (debugging) de scripts
Supongamos que se ha guardado el siguiente script en
un archivo denominado do-errors.sh en el directorio
north-pacific-gyre/2012-07-03 de Nelle:
BASH
# Calcular las estadísticas de los archivos de datos.
for datafile in "$@"
do
echo $datfile
bash goostats $datafile stats-$datafile
doneCuando lo ejecutas:
El output está en blanco. Para averiguar por qué,
vuelve a ejecutar el script utilizando la opción
-x:
¿Cuál es el resultado que muestra? ¿Qué línea es responsable del error?
El indicador -x hace que bash se ejecute en
modo de depuración. Esto muestra cada comando mientras se ejecuta, lo
que te ayudará a localizar errores. En este ejemplo, podemos ver que
echo no está mostrando nada. Hemos creado un error
tipográfico en el nombre de la variable del bucle, la variable
datfile no existe, por lo que devuelve una cadena
vacía.
Key Points
- Guardar comandos en archivos (normalmente llamados scripts de la terminal) para su reutilización.
-
bash filenameejecuta los comandos guardados en un archivo. -
$@se refiere a todos los parámetros de la línea de comandos de un script de la terminal. -
$1,$2, etc., se refieren al primer parámetro de la línea de comandos, al segundo parámetro de la línea de comandos, etc. - Coloque las variables entre comillas si los valores tienen espacios en ellas.
- Dejar que los usuarios decidan qué archivos procesar es más flexible y más consistente con los comandos de Unix.
Content from Encontrando archivos
Last updated on 2023-04-24 | Edit this page
Estimated time: 15 minutes
Overview
Questions
- ¿Cómo puedo encontrar archivos?
- ¿Cómo puedo encontrar algunas cosas dentro de mis archivos?
Objectives
- Usar
greppara seleccionar las líneas de archivos de texto que coincidan con patrones simples. - Usar
findpara encontrar archivos cuyos nombres coincidan con patrones simples. - Usar la respuesta de un comando como parámetro de entrada para otro comando.
- Explicar lo que se entiende por archivos de ‘texto’ y ‘binarios’, y por qué muchas herramientas comunes no manejan bien estos últimos.
De la misma manera que muchos de nosotros ahora usamos “googlear” como un verbo que significa “encontrar”, los programadores de Unix usan cotidianamente la palabra “grep”. “grep” es una contracción de “global/regular expression/print” (global/expresión regular/imprimir), una secuencia común de operaciones en los primeros editores de texto de Unix. También es el nombre de un programa de línea de comandos muy útil.
El comando grep encuentra e imprime líneas en archivos
que coinciden con un patrón. Para nuestros ejemplos, usaremos un archivo
que contenga tres haikus publicados en 1998 en la revista
Salon. Para este conjunto de ejemplos, Vamos a estar trabajando
en el subdirectorio “writing”:
OUTPUT
The Tao that is seen
Is not the true Tao, until
You bring fresh toner.
With searching comes loss
and the presence of absence:
"My Thesis" not found.
Yesterday it worked
Today it is not working
Software is like that.Del dicho “Para siempre, o cinco años”
Nota: no hemos vinculado a los haikus originales porque parecen ya no estar disponibles en el sitio de Salon. Como Jeff Rothenberg dijo, “La información digital dura para siempre — o cinco años, lo que ocurra primero.”
Busquemos líneas que contengan la palabra “not”:
OUTPUT
Is not the true Tao, until
"My Thesis" not found
Today it is not workingEn este ejemplo, not es el patrón que estamos buscando.
Es bastante simple: cada carácter alfanumérico coincide con sí mismo.
Después del patrón viene el nombre o los nombres de los archivos que
estamos buscando. La salida son las tres líneas del archivo que
contienen las letras “not”.
Vamos a probar un patrón distinto: “The”.
OUTPUT
The Tao that is seen
"My Thesis" not found.Esta vez, las dos líneas que incluyen las letras “The” forman parte del producto de la búsqueda. Sin embargo, una instancia de esas letras está contenida en una palabra más grande, “Thesis”.
Para restringir los aciertos a las líneas que contienen la palabra
“The” por sí sola, podemos usar grep con el
indicador-w. Esto limitará los coincidencias a
palabras.
OUTPUT
The Tao that is seenNota que la palabra o patrón de búsqueda incluye el comienzo y el
final de una línea, no solamente aquellas letras rodeadas de espacios. A
veces, queremos buscar una frase, en vez de una sola palabra. Esto puede
hacerse fácilmente con grep usando la frase entre
comillas.
OUTPUT
Today it is not workingHemos visto que no requerimos comillas alrededor de palabras simples, pero es útil utilizar comillas cuando se buscan varias palabras consecutivas. También ayuda a facilitar la distinción entre el término o frase de búsqueda y el archivo en el que se está buscando. Utilizaremos comillas en los próximos ejemplos.
Otra opción útil es -n, que numera las líneas que
coinciden:
OUTPUT
5:With searching comes loss
9:Yesterday it worked
10:Today it is not workingAquí, podemos ver que las líneas 5, 9 y 10 contienen las letras “it”.
Podemos combinar opciones (es decir, flags) como lo
hacemos con otros comandos de Unix. Por ejemplo, vamos a encontrar las
líneas que contienen la palabra “the”. Podemos combinar la opción
-w para encontrar las líneas que contienen la palabra “the”
con -n para numerar las líneas que coinciden:
OUTPUT
2:Is not the true Tao, until
6:and the presence of absence:Ahora queremos usar la opción -i para hacer que nuestra
búsqueda sea insensible a mayúsculas y minúsculas:
OUTPUT
1:The Tao that is seen
2:Is not the true Tao, until
6:and the presence of absence:Ahora, queremos usar la opción -v para invertir nuestra
búsqueda, es decir, queremos que obtener las líneas que NO contienen la
palabra “the”.
OUTPUT
1:The Tao that is seen
3:You bring fresh toner.
4:
5:With searching comes loss
7:"My Thesis" not found.
8:
9:Yesterday it worked
10:Today it is not working
11:Software is like that.grep tiene muchas otras opciones. Para averiguar cuáles
son, podemos escribir:
OUTPUT
Usage: grep [OPTION]... PATTERN [FILE]...
Search for PATTERN in each FILE or standard input.
PATTERN is, by default, a basic regular expression (BRE).
Example: grep -i 'hello world' menu.h main.c
Regexp selection and interpretation:
-E, --extended-regexp PATTERN is an extended regular expression (ERE)
-F, --fixed-strings PATTERN is a set of newline-separated fixed strings
-G, --basic-regexp PATTERN is a basic regular expression (BRE)
-P, --perl-regexp PATTERN is a Perl regular expression
-e, --regexp=PATTERN use PATTERN for matching
-f, --file=FILE obtain PATTERN from FILE
-i, --ignore-case ignore case distinctions
-w, --word-regexp force PATTERN to match only whole words
-x, --line-regexp force PATTERN to match only whole lines
-z, --null-data a data line ends in 0 byte, not newline
Miscellaneous:
... ... ...Utilizando grep
Haciendo referencia a haiku.txt presentado al inicio de
este tema, qué comando resultaría en la salida siguiente:
OUTPUT
and the presence of absence:grep "of" haiku.txtgrep -E "of" haiku.txtgrep -w "of" haiku.txtgrep -i "of" haiku.txt
Caracteres especiales o comodines
La verdadera ventaja de grep no proviene de sus
opciones; viene del hecho de que los patrones pueden incluir comodines.
(El nombre técnico para estos son expresiones
regulares, que es lo que significa el “re” en “grep”.) Las
expresiones regulares son complejas y poderosas. Nota: Si quieres
realizar búsquedas complejas, y quieres saber más detalles mira la
lección de expresiones
regulares. Como prueba, podemos encontrar líneas que tienen una ‘o’
en la segunda posición, por ejemplo:
OUTPUT
You bring fresh toner.
Today it is not working
Software is like that.Utilizamos el indicador -E y ponemos el patrón entre
comillas para evitar que el shell intente interpretarlo. (Si el patrón
contiene un *, por ejemplo, el shell intentaría expandirlo
antes de ejecutar grep.) El ^ en el patrón de búsqueda
indica que la coincidencia debe ser al inicio de la línea. El
. coincide con un solo carácter (como ? en el
shell), mientras que el o coincide con una ‘o’ real que en
este caso viene a ser el segundo caracter.
Seguimiento de una especie
Leah tiene varios cientos de archivos de datos guardados en un directorio, cada uno de los cuales tiene el formato siguiente:
2013-11-05,deer,5
2013-11-05,rabbit,22
2013-11-05,raccoon,7
2013-11-06,rabbit,19
2013-11-06,deer,2Quiere escribir un script de shell que tome un
directorio y una especie como parámetros de línea de comandos y que le
devuelva un archivo llamado species.txt que contenga una
lista de fechas y el número de individuos de esa especie observados en
esa fecha, como este archivo de números de conejos:
2013-11-05,22
2013-11-06,19
2013-11-07,18Escribe estos comandos y pipes en el orden correcto para lograrlo:
Sugerencia: usa man grep para buscar cómo seleccionar
texto recursivamente en un directorio usando grep y man cut
para seleccionar más de un campo en una línea. Encuentra un ejemplo en
el siguiente archivo
data-shell/data/animal-counts/animals.txt
Mujercitas
Tú y tu amigo tienen una desacuerdo, después de terminar de leer
Little Women de Louisa May Alcott. De las cuatro hermanas en el
libro, Jo, Meg, Beth, y Amy, tu amigo piensa que Jo era la más
mencionada. Tú, sin embargo, estás segura de que era Amy.
Afortunadamente tu tienes un archivo llamado
LittleWomen.txt en data/, que contiene el texto completo de
la novela. Utilizando un bucle for, ¿cómo tabularías el
número de veces que cada una de las cuatro hermanas es mencionada?
Sugerencia: una solución sería emplear los comandos grep
y wc y un |, mientras que otra solución podría
utilizar opciones de grep. Normalmente hay más de una forma
para solucionar una tarea de programación. Cada solución es seleccionada
de acuerdo a la combinación entre cuál es la que produce el resultado
correcto, con mayor elegancia, de la manera más clara y con mayor
velocidad.
for sis in Jo Meg Beth Amy
do
echo $sis:
grep -ow $sis LittleWomen.txt | wc -l
doneAlternativa, menos eficiente:
for sis in Jo Meg Beth Amy
do
echo $sis:
grep -ocw $sis LittleWomen.txt
doneEsta solución es menos eficiente porque grep -c
solamente reporta el número de las líneas. El número total de
coincidencias que es reportado por este método va a ser más bajo si hay
más de una coincidencia por línea.
Mientras grep encuentra líneas en los archivos, El
comando find busca los archivos. Una vez más, tienes muchas
opciones. Para mostrar cómo funcionan las más simples, utilizaremos el
árbol de directorios que se muestra a continuación.

El directorio writing de Nelle contiene un archivo
llamado haiku.txt y tres subdirectorios:
thesis (que contiene un archivo tristemente vacío,
empty-draft.md), data (que contiene dos
archivos LittleWomen.txt , one.txt y
two.txt), un directorio tools que contiene los
programasformat y stats, y un subdirectorio
llamado old, con un archivo oldtool.
Para nuestro primer comando, ejecutemos find ..
OUTPUT
.
./data
./data/one.txt
./data/LittleWomen.txt
./data/two.txt
./tools
./tools/format
./tools/old
./tools/old/oldtool
./tools/stats
./haiku.txt
./thesis
./thesis/empty-draft.mdComo siempre, el . por sí mismo significa el directorio
de trabajo actual, que es donde queremos que empiece nuestra búsqueda.
La salida de find es el nombre de cada archivo
y directorio dentro del directorio de trabajo actual.
Esto puede parecer inútil al principio, pero find tiene
muchas opciones para filtrar la salida y en esta lección vamos a
descubrir algunas de ellas.
La primera opción en nuestra lista es -type d que
significa “encontrar directorios”. Por supuesto que la salida de
find serán los nombres de los cinco directorios en nuestro
pequeño árbol (incluyendo .):
OUTPUT
./
./data
./thesis
./tools
./tools/oldSi cambiamos -type d por -type f, recibimos
una lista de todos los archivos:
OUTPUT
./haiku.txt
./tools/stats
./tools/old/oldtool
./tools/format
./thesis/empty-draft.md
./data/one.txt
./data/LittleWomen.txt
./data/two.txtAhora tratemos de buscar por nombre:
OUTPUT
./haiku.txtEsperábamos que encontrara todos los archivos de texto, Pero sólo
imprime ./haiku.txt. El problema es que el shell amplía los
caracteres comodín como * antes de ejecutar los
comandos. Dado que *.txt en el directorio actual se expande
a haiku.txt, El comando que ejecutamos era:
find hizo lo que pedimos, pero pedimos la cosa
equivocada.
Para conseguir lo que queremos, vamos a hacer lo que hicimos con
grep: escribe * txt entre comillas simples
para evitar que el shell expanda el comodín *. De esta
manera, find obtiene realmente el patrón
*.txt, no el nombre de archivo expandido
haiku.txt:
OUTPUT
./data/one.txt
./data/LittleWomen.txt
./data/two.txt
./haiku.txtListar vs. Buscar
ls yfind se pueden usar para hacer cosas
similares dadas las opciones correctas, pero en circunstancias normales,
ls enumera todo lo que puede, mientras que
find busca cosas con ciertas propiedades y las muestra.
Como mencionamos anteriormente, el poder de la línea de comandos
reside en la combinación de herramientas. Hemos visto cómo hacerlo con
pipes, veamos otra técnica. Como acabamos de ver,
find . -name '*.txt' nos da una lista de todos los archivos
de texto dentro o más abajo del directorio actual. ¿Cómo podemos
combinar eso con wc -l para contar las líneas en todos esos
archivos?
La forma más sencilla es poner el comando find dentro de
$():
OUTPUT
11 ./haiku.txt
300 ./data/two.txt
21022 ./data/LittleWomen.txt
70 ./data/one.txt
21403 totalCuando el shell ejecuta este comando, lo primero que hace es ejecutar
lo que esté dentro del $(). Luego reemplaza la expresión
$() con la salida de ese comando. Dado que la salida de
find son los cuatro nombres de directorio
./data/one.txt, ./data/LittleWomen.txt,
./data/two.txt, y ./haiku.txt, el shell
construye el comando:
que es lo que queríamos. Esta expansión es exactamente lo que hace el
shell cuando se expanden comodines como * y ?,
pero nos permite usar cualquier comando que deseemos como nuestro propio
“comodín”.
Es muy común usar find y grep juntos. El
primero encuentra archivos que coinciden con un patrón; el segundo busca
líneas dentro de los archivos que coinciden con otro patrón. Aquí, por
ejemplo, podemos encontrar archivos PDB que contienen átomos de hierro
buscando la cadena “FE” en todos los archivos .pdb por
encima del directorio actual:
OUTPUT
../data/pdb/heme.pdb:ATOM 25 FE 1 -0.924 0.535 -0.518Buscando coincidencias y restando
-v es una opción de grep que invierte la
coincidencia de patrones, de modo que sólo las líneas que no
coinciden con el patrón se imprimen. Dado esto ¿cuál de los siguientes
comandos encontrarán todos los archivos en /data cuyos
nombres terminan en s.txt (por ejemplo,
animals.txt or planets.txt), pero no
contienen la palabra net? Después de pensar en tu
respuesta, puedes probar los comandos en el directorio
data-shell.
find data -name '*s.txt' | grep -v netfind data -name *s.txt | grep -v netgrep -v "temp" $(find data -name '*s.txt')- Ninguna de las anteriores.
La respuesta correcta es 1. Poniendo la expresión entre comillas,
evita que el shell la expanda, y luego lo pasa al comando
find.
La opción 2 es incorrecta porque el shell expande *s.txt
en lugar de mandar el nombre correcto al find.
La opción 3 es incorrecta porque busca en los contenidos de los archivos las líneas que no coinciden con “temp”, en lugar de buscar los nombres de los archivos.
Archivos binarios
Nos hemos centrado exclusivamente en encontrar cosas en archivos de
texto. ¿Y si sus datos se almacenan como imágenes, en bases de datos, o
en algún otro formato? Una opción sería extender herramientas como
grep para manejar esos formatos. Esto no ha sucedido, y
probablemente no se hará, porque hay demasiados formatos
disponibles.
La segunda opción es convertir los datos en texto, o extraer los bits
de texto de los datos. Este es probablemente el enfoque más común, ya
que sólo requiere generar una herramienta por formato de datos (para
extraer información). Por un lado, facilita realizar las cosas simples.
Por el contrario, las cosas complejas son generalmente imposibles. Por
ejemplo, es bastante fácil escribir un programa que extraiga las
dimensiones X, Y de los archivos de imagen para que podamos después usar
grep, pero ¿cómo escribir algo para encontrar valores en
una hoja de cálculo cuyas celdas contienen fórmulas?
La tercera opción es reconocer que laterminal y el procesamiento de texto tiene sus límites, y en caso necesario debes utilizar otro lenguaje de programación. Sin embargo, el shell te seguirá siendo útil para realizar tareas de procesamiento diarias.
La terminal de Unix es más antiguo que la mayoría de las personas que lo usan. Ha sobrevivido tanto tiempo porque es uno de los ambientes de programación más productivos jamás creados — quizás incluso el más productivo. Su sintaxis puede ser críptica, pero las personas que lo dominan pueden experimentar con diferentes comandos interactivamente, y luego utilizar lo que han aprendido para automatizar su trabajo. Las interfaces gráficas de usuario pueden ser más sencillas al principio, pero el shell sigue invicto en segunda instancia. Y como Alfred North Whitehead escribió en 1911, “La civilización avanza extendiendo el número de operaciones importantes que podemos realizar sin pensar en ellas.”
- Encuentra todos los archivos con una extensión
.daten el directorio actual - Cuenta el número de líneas que contiene cada uno de estos archivos
- Ordena la salida del paso 2. numéricamente
Búsqueda de archivos con propiedades diferentes
El comando find puede recibir varios otros criterios
conocidos como “tests” para localizar archivos con atributos
específicos, como tiempo de creación, tamaño, permisos o dueño. Explora
el manual con man find y luego escribe un solo comando para
encontrar todos los archivos en o debajo del directorio actual que han
sido modificados por el usuario ahmed en las últimas 24
horas.
Sugerencia 1: necesitarás utilizar tres tests:
-type,-mtime y -user.
Sugerencia 2: El valor de -mtime tendrá que ser negativo
— ¿por qué?
Key Points
-
findencuentra archivos con propiedades específicas que coinciden con los patrones especificados. -
grepselecciona líneas en archivos que coinciden con los patrones especificados. -
--helpes un indicador usado por muchos comandos bash y programas que se pueden ejecutar desde dentro de Bash, se usa para mostrar más información sobre cómo usar estos comandos o programas. -
man commandmuestra la página del manual de un comando. -
$(comando)contiene la salida de un comando.