What is special in data science project ?
Last updated on 2023-02-13 | Edit this page
Overview of this training material
Overview
Questions
- Get an overview of the training material
- understand how the different aspects of this material relates to one another
Objectives
- Understand how this training material is organised.
Team and data science
The principles taught in this course can be applied to any research project. It will help project manager to work with online tools, with people with specialised skillsets, and with a project involving some code writing and code reuse. The goal is to produce a reproducible data analysis in modern research context.
It requires some specific and some non-specific project management actions. This course covers a large panel of action to perform before, during and after the project is conducted.
This program will teach you best practices in data science project management and how to appyly them to research project. This material will help you to manage a research project that comprise some online collaborative working, has a relatively big team, where people have complementary skills, use coding or programming, as well as the reuse of code, and last but not least, aim at producing a reproducible analysis, as is pictured below.
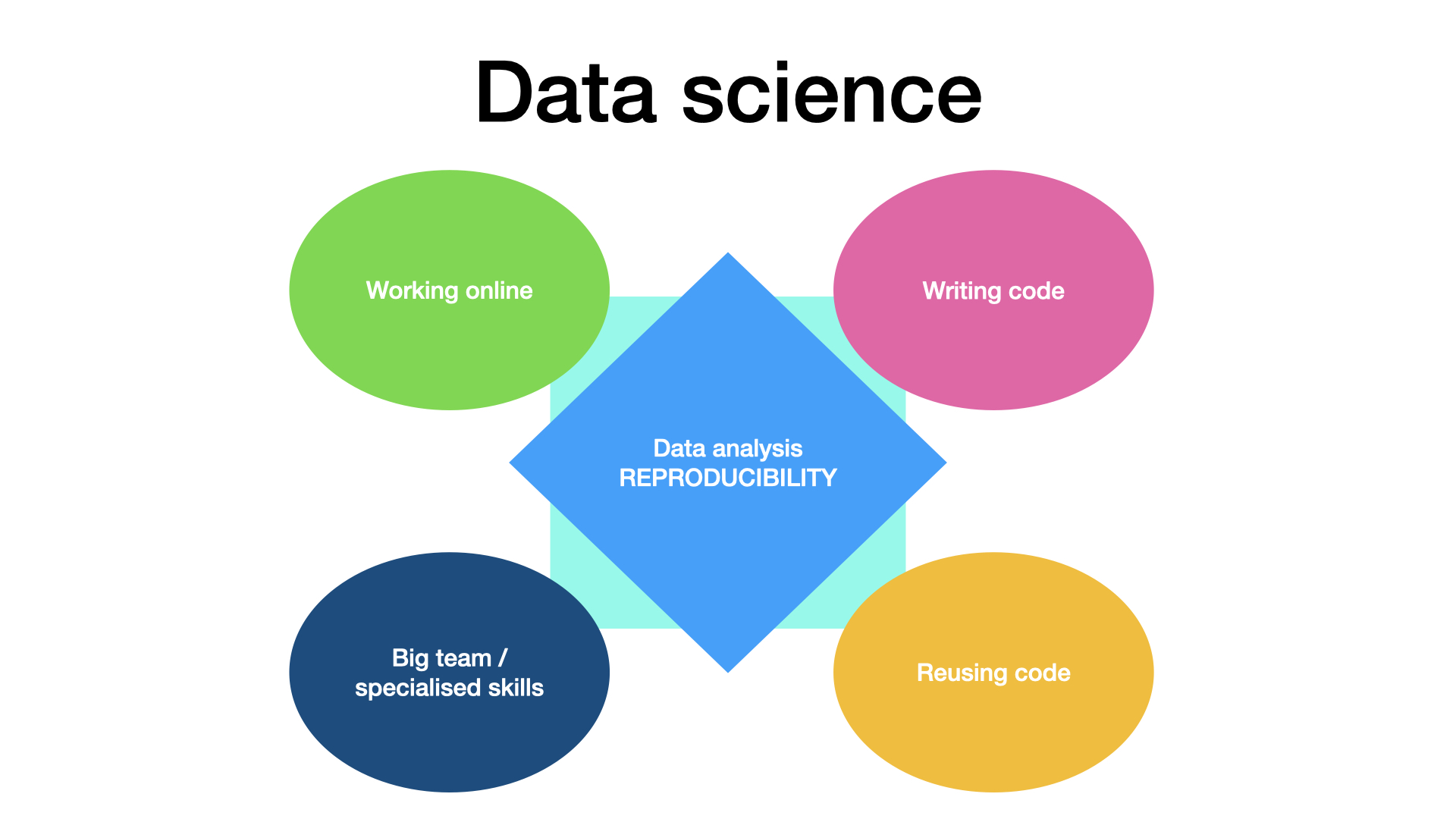
Here we give an short overview of the topics that will be covered in this course. Note that the course episode split follows a different logic, and you will find training linked to each five of these data science specifics in most episodes.
Online work
When part of the work happens online, it becomes very easy to loose track of what documents are where, what tools were used (by whom), and who is doing what. Discussions are also more difficult to organise and meetings are more complex to drive. In this course, we will look at different elements that make this work easier.
Af first, there should be one entry point for the project, where
every team member can find the main documentation as well as links to
other documents and data. This starts with setting
one main URL when setting up the project, as well as using
good readme files and templates. The information needs to be updated
during the project and shared with the whole team.
The use of online project management tool (like kaban boards for todo list) can also help members of the team to coordinate their work, and follow their achievements.
Team science
Because teams can be big, and quite heterogeneous in terms of skills (especially computer and programming skills), it is important to follow best practice of team building.
In particular, one should set reasonable goals and milestones for the project, and document them in the main documentation. It is also important that every team member knows what his part is, and that the work is well distributed.
One should make sure every team member is able to use the communication tools set for the team, and take particular care of the organisation of meetings. Data and code should be documented (and this documentation work should be fostered), such that every team member can follow and reuse the work of the other team members.
Involves coding
When data analysis is done via a programming language, things become mostly easier, but this facility has some drawbacks, as well as some effects on data management practice.
First, a data analysis workflow will now start with the computer reading the raw data. This means that the choice of the data format for the raw data may change, and that manually gathered data should be (easily) computer readable. This is particularly important for spreadsheets, as a lot of time can be saved by designing the spreadsheet in a tidy format.
Second, statistical analysis and data representation in figures will now be much easier to perform, making p-hacking and harking practices very easy to do, even involuntarily. Researcher have to actively make sure their analysis is not flawed.
Third, making errors in the code may have larger effects than making error in a manual analysis. However, errors are easier to spot (doing code reviews and tests) and when the code is corrected, the results are immediately corrected, too.
Involves reuse of code
Very soon in a research project, writing code consist mostly of taking code written by someone else and applying it (with some tweaks sometimes) to one own data. We will look at ways to find relevant code, make sure it can be trusted, make sure you can legally use it, and ways to cite it (to give recognition the initial software engineer deserves).
In addition, code written in the project will probably be reused, too. We will look into best practices to make this reuse easier, both in how the code is written (modularity, documentation, tests) and in how the code is shared (license, repository, version control, release, users instruction, developers instructions).
Reproducibility
At the core of data science, the analysis reproducibiliy is both a goal and a huge advantage (in terms of research transparency, trustworthiness and work efficiency). The use of code is not enough to get a reproducible analysis, one needs to have access to both the code and the data used to produce the research result, a concept called provenance. This may not be trivial, especially if several version of the code and of the data exist.
In this course, we will have a strong emphasis on version control, while we will introduce the concepts (and some tools) of provenance, as well as literate programming (reproducible reports and executable papers), where the code, the figure and explanatory text are bound in the same file.
Key Points
- content organisation